Некоторое время тому назад я ознакомился с чудесной методикой по анализу художественных произведений. Методику Story Grid разрабатывал на протяжении двадцати лет зарубежный редактор Shawn Coyne и мне она показалась весьма и весьма интересной. Еще бы, ведь при помощи Story Grid можно найти уязвимые места в вашем (или чужом) произведении. И не просто найти, а понять, что именно необходимо исправить в конкретном месте дабы улучшить произведение в целом.
Именно по этой причине я решил попробовать полученные знания на практике. А как можно их использовать? Тут вариантов всего два. Либо попытаться «прогнать» через Story Gird чужую книгу, либо попробовать написать свою в максимальном приближении к рекомендациям Шона. Я решил пойти по второму пути. Ведь применение Story Grid в реальном деле позволит не только закрепить материал, но и позволит (надеюсь) улучшить конечный результат.
Если мой любопытный читатель еще не знаком с тем, что такое Story Grid, то я настоятельно рекомендую ознакомиться с методикой как минимум в моей статье. Ну а если попытаться описать Story Grid в двух словах, то редактор (или автор) собирает метаданные о тексте, а затем анализирует полноту раскрытия типов сюжетов, а заодно и метаболизм изменения так называемого опыта героев. По ходу анализа, а по мнению автора методики, проводить процедуру разбора произведения следует как минимум на первом черновике всего текста, собираются и записываются сведения о событиях, обязательных сценах выбранного типа жанра, локации, герои и прочее. Если сам текст произведения можно назвать данными, то собираемые сведения есть ни что иное, как метаданные (данные о данных). Затем к метаданным применяются методы анализа, в том числе и графического. Анализ можно провести на листке бумаги, а можно применить офисные пакеты (в своей статье про Story Grid я привел несколько шаблонов для Microsoft Office).
Но поскольку в большинстве, даже в подавляющем большинстве случаев, все рукописи создаются исключительно в электронном виде, то мне захотелось немного облегчить себе труд и как-то постараться автоматизировать весь процесс сбора метаданных и частично их последующий анализ. Более того, я решил применить еще один, небольшой, но как мне тогда казалось, очень полезный трюк. Если создавать метаданные параллельно вместе с данными, то таким образом можно сэкономить кучу времени. Именно так я справедливо и полагал.
И дабы проверить свою теорию и соединить полученные знания с практикой, я решил написать небольшой рассказ общим объемом до 30.000 слов, даже скорее повесть, если судить по размеру текста, что соответствует примерно 1/3 полновесного романа. А во время написания попрактиковаться в применении методики. Весь объем текста я предварительно разделили на 3 акта. В первом и последних актах у меня поместилось по три главы, а во втором — шесть глав. Каждую главу я рассчитывал, строго следуя рекомендациям Шона, из объема чуть больше двух тысяч слов. И да, одна глава у меня равняется одной сцене. Итого, на весь рассказ, ну или повесть, ушло 12 глав или 12 сцен.
В качестве внешнего жанра в рассказе «Конец вечной энергии», для Storyline A, я выбрал криминальные мотивы, а именно полицейскую историю, рассказанную с точки зрения инспектора полиции в небольшом американском городишке. Ценность на кону, разумеется, справедливость. А как иначе, если это драма максимально приближенная по эмоциям к жизни? Внутренний жанр тесно связан со статусом. Герой в «Конец вечной энергии», а именно так я назвал свое произведение, жаждет профессиональной реабилитации и готов не щадить живот свой, но только бы восстановить поруганный Status Quo.
Программно-аппаратный комплекс писателя
В давние времена люди писали свои манускрипты от руки. Делали ошибки, зачеркивали слова, выкидывали листки бумаги в мусор. Потом перьям и шариковым ручкам на смену пришли печатающие машинки. Что облегчило последующий труд по разбору всей писанины в десятки и сотни тысяч раз, ведь далеко не у каждого писателя красивый и понятный почерк. И только в эпоху всеобщей компьютеризации, когда все начали использовать персональные компьютеры для набора текстов, наконец-то настала эра благоденствия. А те немногие ретрограды, принципиально нежелающие переходить на электронные «печатающие машинки», остались не у дел и успешно вымерли, покрывшись слоем бумажных ошметков.
Применение компьютера для написания художественных произведений неимоверно удобно. Не буду перечислять все достоинства этого метода, отмечу лишь два. В электронную версию произведения очень легко вносить изменения. И крылатая фраза «Что написано пером, не вырубишь и топором» полностью потеряла свое значение, поскольку, то, что написано на компьютере, можно и нужно с легкостью менять. Впрочем, набирать текст на клавиатуре куда проще, нежели стараться написать аналогичный объем от руки. Кто моно писал конспектов лекций, тот знает, что рука при письме изрядно устает.

Планшет Chuwi Hi8 с Bluetooth-клавиатурой оказался вполне неплохой печатающей машинкой
Кстати, рассказ-повесть «Конец вечной энергии» был написан мною на планшете Chuwi Hi8. Небольшой планшет, со скромной диагональю и высоким разрешением, позволил мне, почти в походных условиях, не только реализовать задумку, но и провести анализ написанного. Удивительно, но благодаря высокому разрешению, даже скромная диагональ экрана не вызывала никакого дискомфорта при длительной работе. Разумеется, для набора текста применялась Bluetooth-клавиатура, поскольку ввод текста с экранной клавиатуры уместен лишь при небольших объемах. Текст набирался в полноценной версии MS Word под Windows.
Как ни крути, использование MS Word стало почти что стандартом de facto для работы с текстами. Хочу заметить, что Word вовсе не текстовой редактор. MS Word — текстовой процессор, продукт позволяет не только редактировать тексты, но и выполнять множество других задач, например, проверку правильности написания, форматирование, подбор синонимов и прочее, прочее, прочее. А текстовой редактор — это Notepad в Windows. Вот там, помимо функций непосредственно редактирования текста, нет ничего. Строго и аскетично. Возможно, что есть на свете идеалисты, использующие исключительно Notepad или другой редактор, но оставим их за скобками как исключения.
Некоторые возразят, что мол, есть же на рынке множество других офисных продуктов, выступающих альтернативами пакету «редмонского гиганта». Да, они есть. Присутствуют. Но живьем использующих их и для создания чего-то более крупного, нежели табличка с расписанием уроков, я лично не встречал. Поэтому могу смело заявить, что среди всего многообразия текстовых процессоров, для написания лучше использовать MS Word. Как минимум, он подведет меньше, нежели его клоны.
Тем не менее, необходимо учитывать, что кроме универсальных текстовых процессоров, типа того же Word, есть и специализированные редакторы, разработанные непосредственно для писателей, сценаристов, новеллистов и прочих прозаиков. Некоторое время тому назад, я тестировал одно из таких решений Scrivener. Решение очень и очень неплохое, но из-за проблем с русским языком, оформлением конечного текста и перманентными проблемами при синхронизации посредством облачных технологий, пришлось отказаться от вполне удобного инструмента.
Почему MS Word не подходит для автоматизации работы по процессу Story Grid
В своем обзоре методики Story Grid, я подготовил несколько русскоязычных шаблонов для облегчения работы по Story Grid. Еще раз напомню, что вся суть метода заключается в сборе и анализе метаданных по обрабатываемому тексту. А автоматизация этого процесса, как раз и заключается в упрощении сбора метаданных. Представьте, вы пишите свой текст, а попутно заполняете дополнительные сведения, не отходя от кассы.
Но проблема в том, что в MS Word нет возможности нормальной работы с метаданными с привязкой их к тексту. Word вырос, благодаря длительной эволюции, из обычного текстового редактора в полноценный и развитой продукт. А его клоны, просто взяли и повторили функционал Word, не задумываясь над расширением функциональности. В Word есть возможности, да и то далеко запрятанная и трудно извлекаемая, по изменению метаданных файла. Но они, по большей части, нужны для систем документооборота, а не для писателей.
В Word нет нормальной сегрегации частей текста друг от друга. Весь файл, вся книга — единое пространство текста. Для обычной работы может быть это и удобно, но если вы начинаете внедрять процессы, ориентированные на принцип «разделяй и властвуй», то все, приехали. Тут неопытного писателя поджидают различного рода проблемы. Решить проблему с отсутствием сегрегации можно либо используя физически разные файлы для каждого блока текста, либо при помощи «навигации» и скрытию текстов при помощи заголовков различных уровней.
При активной работе с большим текстом хочется иметь какую-либо защиту своих трудов. Но Word, по умолчанию, не поддерживает никакие варианты версиализации. А бывает полезно вернуться к одной из прошлых версий, посмотреть, что было там написано, может быть откатиться на нее. Приходится уповать только на ручное резервное копирование или же полагаться на такие механизмы как File History в Windows, Time Machine у Apple, OneDrive и аналогичные сервисы. Но версиализируется в них целый файл, а не отдельная его часть.
Хотя проблемы с сегрегацией и версиализацией не являются критичными для процесса автоматизации, а вот отсутствие возможности параллельного ведения и хранения метаданных вкупе с данными — есть основное препятствие при попытке автоматизировать процесс Story Grid в Word. Попробуем рассмотреть возможные варианты.
Варианты работы с метаданными в Word
Идеально возможным решением по автоматизации Story Grid в Word, на мой взгляд, является сохранение метаданных прямо в Word, затем при помощи макроса пересборка метаданных в виде Excel книги. Выглядит вполне реализуемо, как по технической базе, так и по трудозатратам. Осталось только понять, где хранить сами метаданные.
Скрытый текст
В MS Word присутствует функция, позволяющая сделать некоторый текст скрытым. В настройках шрифта присутствует специальный пункт, позволяющий скрыть текст. В обычном режиме редактирования, печати или просмотра видно его не будет. Более того, помеченный скрытым текст не учитывается в статистике подсчета слов и символов в тексте.
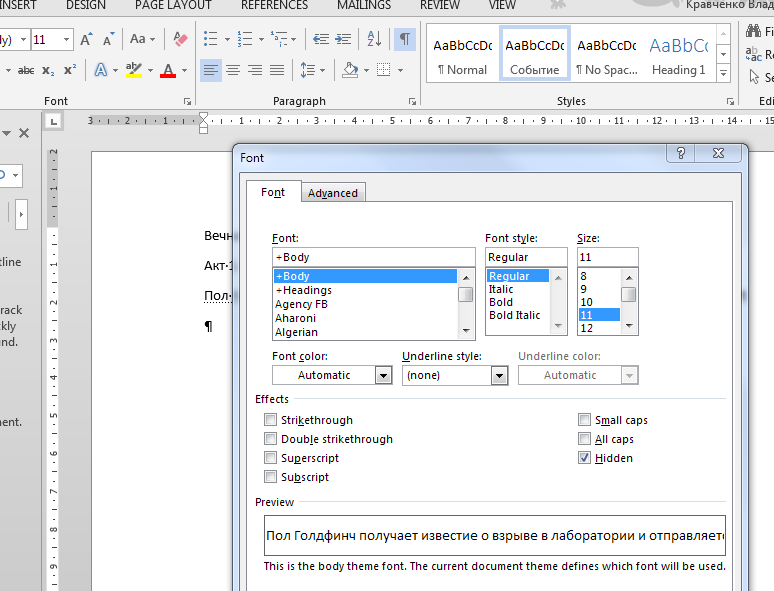
Настройка скрытого текста в MS Word
Для просмотра или редактирования скрытого текста необходимо включить его отображение либо через меню, либо при помощи комбинации CTRL+*. В таком случае, помимо скрытого текста на экране будут отображаться еще и прочие символы форматирования. Кому-то такой режим с отображением специальных символов даже больше по душе, нежели обычный режим.
Для придания тексту статуса скрытого можно пойти двумя путями: либо назначать каждому кусочку признак индивидуально, либо настроить соответствующий стиль.
Невидимое содержимое
В Word начиная с версии 2010 присутствует возможность, хотя и очень условная, по манипуляции невидимым содержимым (Invisible Content). Для чего точно была реализована функция с невидимым содержимым в Word, никто толком не знает. Но в нее заносятся некоторые метаданные для всего файла, например, автор документа или последний редактирующий.
При отправке документа за пределы компании рекомендуется очищать невидимое содержимое для исключения утечки чувствительной информации. Для целей хранения метаданных по отдельным частям текста невидимое содержимое — бесполезная функция.
Настраиваемые XML данные
Поскольку новые форматы офисных файлов от Microsoft построены на принципах XML и позволяют упростить обмен и совместимость между версиями, то, казалось бы, что функция «Настраиваемые XML данные» (Custom XML Data) именно тот механизм, который позволит хоть как-то решить задачу. Но на практике функция оказалась полностью неприменимой для целей хранения метаданных в рамках процесса Story Gird. Более того, механизм работы с Custom XML Data, по крайней мере в моих версиях офиса, заблокирован производителем.
Настраиваемые свойства
«Настраиваемые свойства» (Custom Properties) в Word настолько сложная штука, что описать ее в двух словах и нельзя. Да и реализована она, мягко говоря, не совсем прямо.
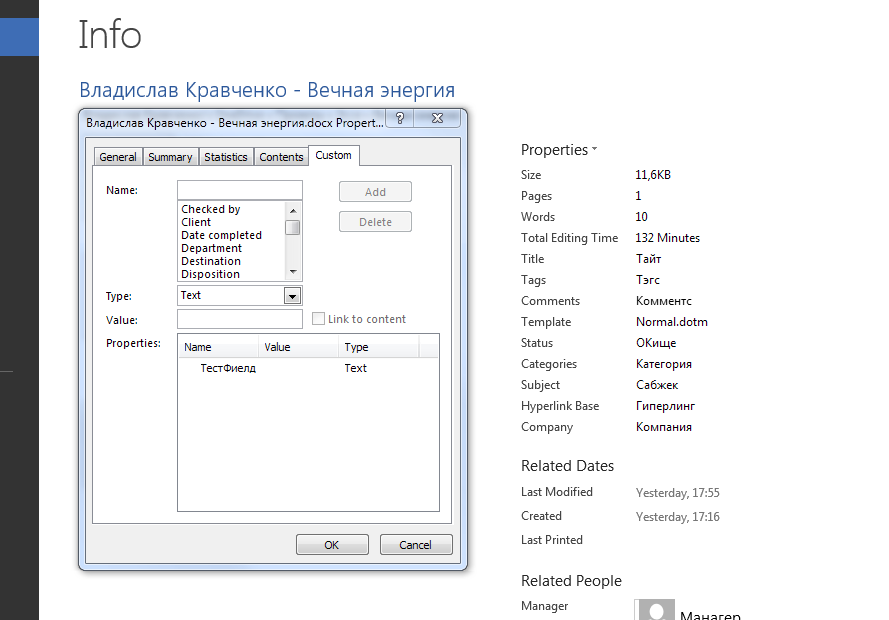
Просмотр настраиваемых параметров в MS Word
У каждого Word файла есть свои свойства. Они принадлежат целиком всему файлу. В более-менее современных версиях до них можно добраться через меню «Файл», а затем «Свойства». Отчасти это все те же данные, что и в «Невидимом содержимом», но здесь их немного больше, да и добавить можно свои.
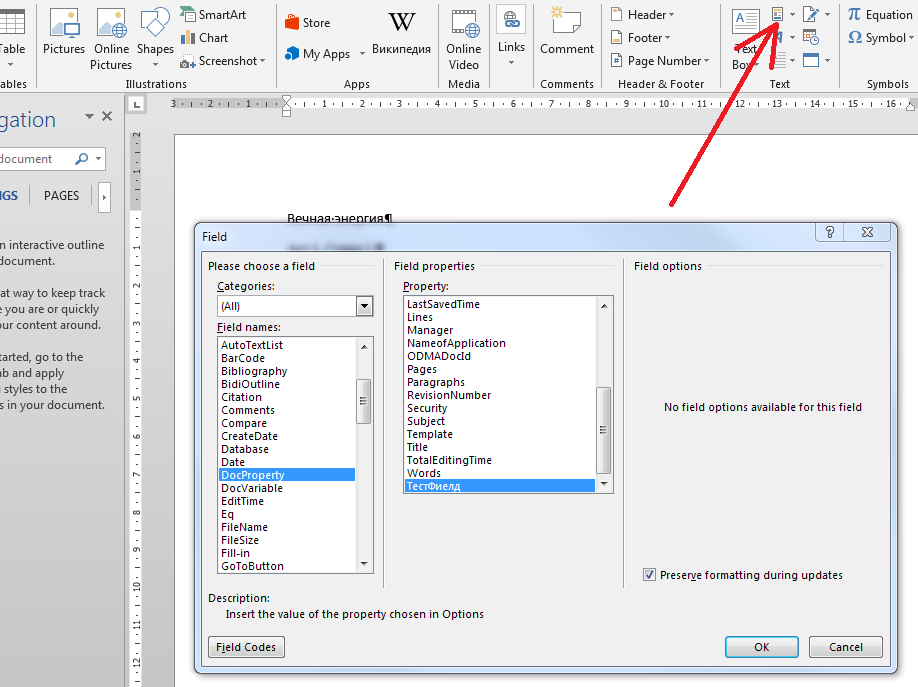
Создание настраиваемого параметра в MS Word
Если ввод данных в свойства осуществляется через меню «Файл», то заведение новых свойств, тех самых, настраиваемых, осуществляется через меню «Быстрая вставка» меню «Вставка». Там нам нужно подменю «Поля» с перечислением свойств. В списке нужно найти свойство DocProperty и уже там можно добавить новое поле.
Но, опять же, функция неудобна для целей сбора метаданных по тексту. Ее удел — хранить метаданные для всего документа.
Текстовые блоки со скрытым текстом
Небольшая вариация на тему просто скрытого текста. Резюме — работать неудобно.
Использование комментариев
Комментарий — удобная функция в Word. Комментарий привязывается к конкретному месту текста, позволяет хранить достаточный объем информации, не участвует в подсчетах количества слов и вообще вещь сугубо вспомогательная.
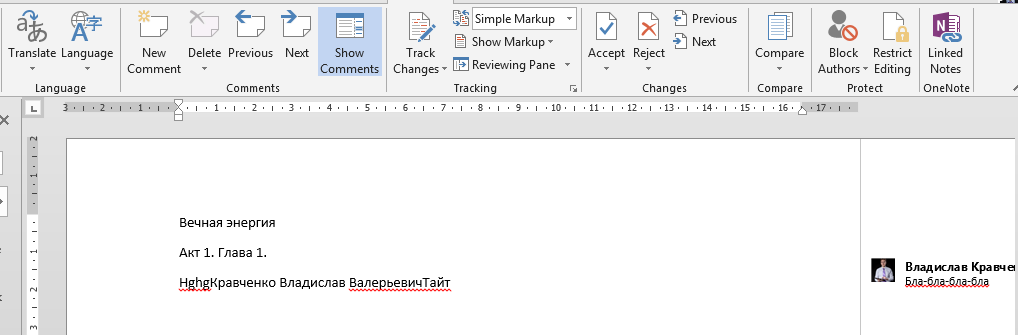
Вариант использования комментариев
На мой взгляд, комментарии вполне можно использовать для идентификации и привязки метаданных к тексту. Стандартные комментарии можно включать и отключать, оптимизируя отображение текста на экране. Важно только проявлять аккуратность при удалении блоков текста, так как вместе с текстом удалятся комментарии, особенно если их отображение выключено.
Экспресс-элементы
Экспресс-элементы (Quick Parts) предназначены для автоматизации добавления стандартных элементов в текст. Вы можете запрограммировать некие блоки, которые затем с легкостью добавлять в нужное место вашего текста. Таким же образом можно запрограммировать и скрытый текст, немного облегчив себе работу применением шаблона.
Практическая реализация
Из всего перечня возможностей, наиболее работоспособными вариантами являются применение скрытого текста или комментариев. Если в скрытый текст или комментарии добавлять метки, по которым в дальнейшем макрос сможет точно опознавать конкретное значение метаданных, то автоматизация вполне возможна. Ориентироваться по отношению к какому блоку текста относится конкретный блок метаданных можно анализируя местоположение блока метаданных. Задача технически реализуемая. И я попробовал ее выполнить на примере своего произведения. В качестве наиболее удобного для меня варианта хранения метаданных, немного поразмыслив, я взял вариант со срытым текстом.
Мой скрытый текст с метаданными располагается в конце каждой главы и сдвигается пока я набираю новый текст. Такое расположение удобнее, чем расположение в начале главы, тем, что метаданные всегда располагаются в непосредственной близости от набираемого текста.
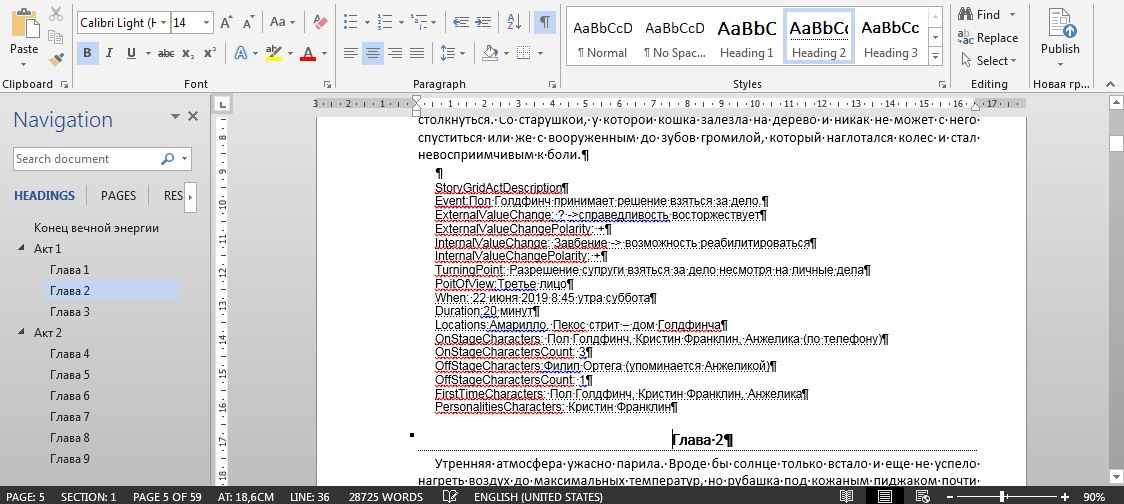
Метаданные для методики Story Grid в виде скрытого текста
Поскольку в методике Story Grid используется изрядное количество типов метаданных, читай каждая колонка в таблице Excel шаблона Story Grid — есть ни что иное, как отдельная частичка метаданных, то все написания наименований метаданных строго закрепляются и отделяются от самих данных метаданных двоеточием. Такая структура позволит в макросе автоматизировать разбор строк.
Проблемы по ходу выполнения
Благодаря свойствам Word, я могу отметить, что на создание рассказа «Конец вечной энергии» у меня ушло около полутора месяцев. Общее время работы над файлом заняло более 260 часов. Однако, в эти часы включено, в том числе, еще и время простоя, когда файл был просто открыт, но непосредственной работы с текстом не велось. Если говорить о затратах непосредственно на написание текста, то на 2000 слов первого черновика у меня уходило порядка двух часов. Что тоже не мало.
Первоначально я пытался заполнять метаданные прямо по ходу написания текста. Ввел в оборот нового персонажа, будь добр занеси информацию про него в блок метаданных, произошло поворотное событие, не забудь его прописать в метаданные. Но на такие записи приходится постоянно отвлекаться, что явно не способствует качеству изливания мысли на «бумагу». Аналогичная проблема возникает, если пытаться заполнять сразу таблицу Excel. Постоянные переключения мешают переработке мысли в буквы, разрушается потоковое состояние, отсутствует восприятие со стороны читателя.
При использовании метаданных в тексте возникают определенные трудности при редактировании, когда требуется внести существенные изменения в текст, особенно в начало главы. Приходится постоянно прокручивать текст вверх-вниз, что особенно мучительно на небольших экранах и длинных текстах.
В целом идею с упрощением и автоматизацией процесса анализа Story Grid можно смело признать фиаско. Заполнять метаданные по ходу написания текста в существующих программных продуктах — идея явно неудачная. Стоит прислушаться к опыту Шона, его друзей, и заполнять таблицы Story Grid после написания первого черновика произведения. Поняв эту нехитрую мысль примерно на середине процесса написания, я решил дальше двигаться традиционным путем, но ни в коем случае не забывая про все наставления и наработки от Шона касательно структуры текста.
Что в результате?
В конце концов, спустя несколько недель труда, рассказ или может быть даже повесть, с горделивым названием «Конец вечной энергии» был завершен в виде первого черновика. Вторым этапом, в полном соответствии с рекомендациями автора Story Grid, я приступил к анализу текста. В мою задачу входило: выявление ключевых моментов, обязательных событий, поворотных точек в моем сюжете.
Напомню, что по сути «Конец вечной энергии» — детектив с научно-популярным уклоном. В рассказе инспектор пытается вывести на чистую воду преступников, хотя удается ему это не без труда. Помимо основной линии А, в рассказе присутствует и линия Б. Если А плотно завязана на перемещение от несправедливости (произошло преступление) к справедливости (наказан преступник), то в Б все немного расплывчатее и сложнее. В Б идет борьба за восстановление профессионального статуса, который пострадал до начала истории и который может быть восстановлен в случае успешного завершения дела.
Помимо двух сюжетных линий (А и Б) в рассказе присутствуют и так называемые обязательные события. Это то, что ждет от детектива читатель. Да, у меня в рассказе (повести) присутствуют сцены допросов, попытки злодеев увести расследование на ложный путь и в виде кульминационного момента все происходящее в линии А переводится в плоскость личного противостояния представителя закона с его нарушителями.
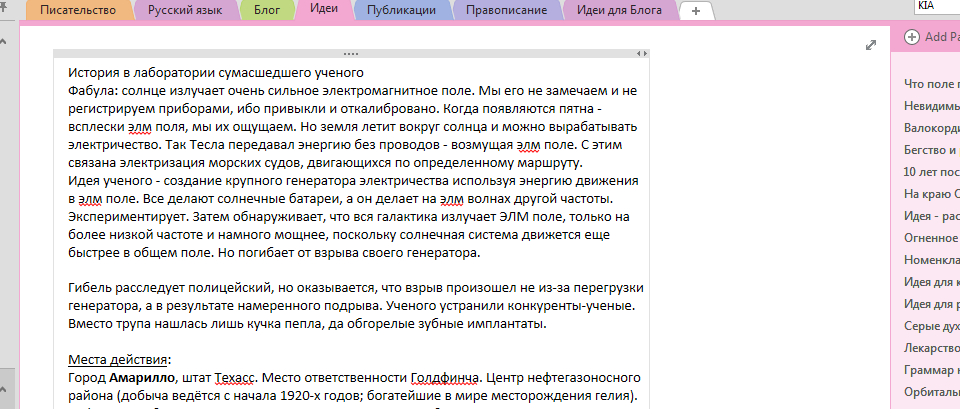
Оформление и развитие идеи истории в OneNote на примере "Конец вечной энергии"
Процесс создания произведения у меня начинается с идеи. Как правило, сама идея может быть чем-то не очень значительным, но обязательно необычным. И вокруг идеи постепенно оборачиваются дополнительные подробности, постепенно крупнозернисто прорисовывается сюжет. Для записей я использую OneNote и похоже, что все его конкуренты, за исключением, пожалуй, EverNote исчезли с рынка. В OneNote я старательно конспектирую основные моменты и ключевые факты. К примеру, если действие происходит где-то, то у этого где-то должен быть свой конкретный адрес или детерминированное местоположение. Шон в своем Story Grid уделяет не мало внимания местоположению и адресам. И не зря. Но я храню в OneNote, а в последствии еще и вынес эту информацию в шаблоны для Story Grid, некие ключевые сведения по персонажам и принадлежащим им объектам материальной культуры. Подобные сведения позволяют не плавать в случае, когда текст набирается длительное время и порой уже начинаешь подзабывать, какого типа был нос у второстепенного персонажа, римский или греческий, или какой автомобиль водит жена главного героя.
Стоит ли планировать развитие сюжетных линий заранее? На мой взгляд нужно. Особенно в случае, когда вы работаете в определенных границах по объему. Часто, на волне энтузиазма, автор растягивает начало своего произведения на многие главы, а окончание вынужден комкать, поскольку он уже явно не помещается в требуемый формат. Спланировать повесть, не говоря о более крупных формах, уже не просто. Нужно продумать все циклы изменения ценностей героев. Понять события, обдумать последствия. Оставлять развитие сюжета на самотек в подобном случае явно не стоит.
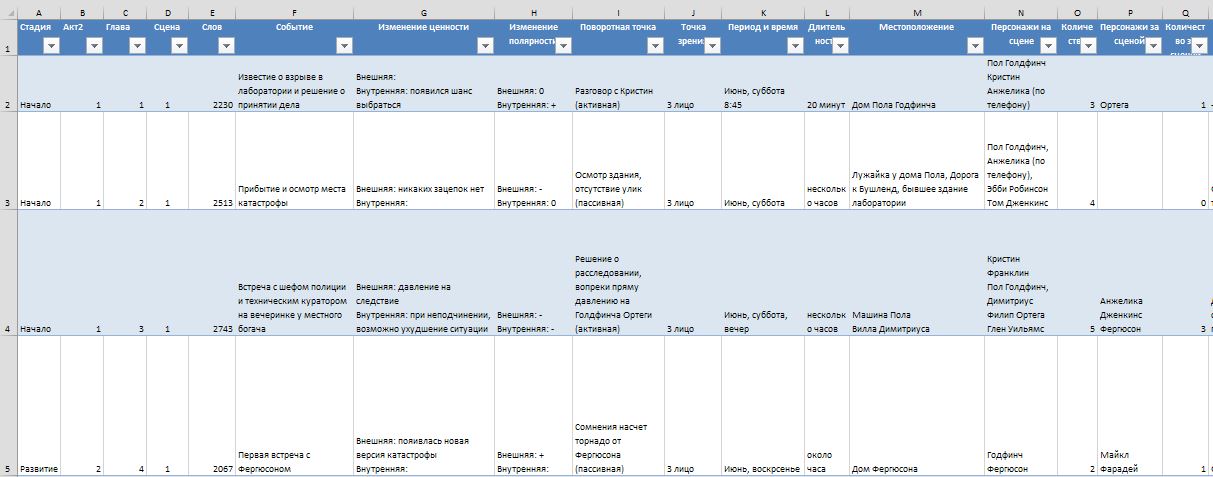
Фрагмент таблицы Story Grid для "Конец вечной энергии"
Итак, после создания первого черновика я заполняю метаданные в таблице Excel. Работать на маленьком по диагонали экране сразу с двумя приложениям не так удобно. Поэтому я переписываю определенные значения сначала в блокнот, а уже из него на лист книги Excel. Основная трудность тут состоит как раз в аналитическом начале автора. Необходимо каждый раз достаточно серьезно напрягаться и формулировать такие понятия, как например, изменение ценности из одного состояния в другое. А поскольку проделать подобное можно далеко не всегда, то я решил немного схитрить и упросить формулировки. Если автор Story Grid старается формулировать изменения в виде непрерывного процесса, например, несправедливость -> справедливость. То я поступил немного иначе, в качестве определения изменения я использовал что-то типа «давление на следствие» или «появилась новая версия». В качестве дополнительного элемента я ввел еще возможность отмечать обязательные сюжетные события. Выделение их вкупе со всеми остальными данными позволяет немного сэкономить время при подготовке графика Story Grid.

График Story Grid для "Конец вечной энергии"
В момент написания, некоторые главы шли не очень хорошо, если не сказать, что их появление на свет сопровождалось интеллектуальными муками. Создаваемый рассказ мне совсем не нравился, даже несмотря на вполне интересную идею. Но. Все дело оказалось в попытке выделения метаданных в процессе написания. На них отвлекались мозговые ресурсы. Собственно, вот еще одна причина не портить творческий процесс, а оставить возможность исправления на следующий этап. Что и было сделано. И чем дальше я продвигался по сюжетной линии без дополнительного анализа текста, тем больше мне нравилась моя повесть (ну или рассказ).
Небольшую трудность в процессе составления графика развития истории заключалась в отсутствии мышки и скромным экраном. Поэтому, окончательную доводку пришлось осуществить уже на стационарном компьютере. Как видно по графику — в каждой главе происходит какое-то изменение. Нет глав, в которых либо герой не решает что-то, либо за него не решают высшие силы. В каждой главе и в каждой сцене присутствуют обязательные условности для криминального жанра. Это либо допросы, либо погони, либо мертвые тела. Все как ожидается любителями жанра. Но хочу сразу предупредить, что условности далеко не шаблонны и просто так нагенерировать их в текст будет равносильно тому, чтобы отдать написание романа полностью роботу.
Ну и наконец анализ изменения ценностей для каждой из сюжетных линий. В небольшом по формату произведении не всегда есть возможность изображать какие-либо сложные фигуры на графике изменения. Но даже в 12 главах можно заметить, что тут нет серьезных колебаний между положительными и отрицательными значениями ценностей, а под конец повествования они расходятся в разных направлениях. Увы, даже в жизни порой наши желания не всегда сбываются все сразу, тем более не стоит ожидать успеха во всех начинаниях героев на страницах криминального произведения.
И если подвести итог, то могу отметить, что методика Story Grid и прочие рекомендации, приведенные в моем обзоре, вполне работают и действительно помогают в процессе создания произведений. Ознакомиться с заполненной книгой Excel с результатами анализа произведения по Story Grid можно по этой ссылке.
PS. У пытливого читателя может возникнуть вопрос, а что с инструментом Foolscap? Когда его заполнять? Во-первых, я его заполнил до начала этапа изложения мысли на «бумагу». Во-вторых, мне пришлось его подкорректировать по итогам редактирования первого черновика. Самое сложное, с чем пришлось столкнуться в Foolscap это то, что стадий в каждой части больше, чем сцен. Другими словами, некоторые главы содержат сцены в которых происходит, например, сразу кризис, кульминация и разрешение. Аналогично и с изменениями ценностей. В Foolscap они даны для каждой стадии, а метаданные у нас собирались по сценам. Но, ничего. Справился.
