
Скромный лучик света в темном царстве невежества
Проблема с нехваткой публичных IPv4 адресов возникла не вчера и даже не позавчера. Когда только на горизонте забрезжил лучик проблем, что IPv4 адресов на всех желающих не хватит, был разработан стандарт IPv6, в котором этих адресов настолько много, что хватит их очень на долго. Но… Переход на новый протокол длится уже более 20 лет, но до сих пор полный переход во всех сферах и направлениях так и не произошел. И похоже, что мы еще довольно долго будем валандаться с ограниченным по количеству публичных адресов наследием прошлого очень долго.
Для чего же нужен IPv6? Для меня лично он работает просто быстрее, чем IPv4. А еще на свое любое устройство с поддержкой IPv6 я могу подключиться откуда угодно. Да и вообще, надо идти в ногу со временем. Сколько же уже можно? Но, к сожалению, несколько из моих провайдеров, не будем показывать пальцами, хотя это Мегафон, MosLine и Билайн, совершенно не спешат переходить на современный протокол. Провайдеров отчасти тормозят такие вещи, как чрезмерно устаревшее оборудование, отсутствие квалифицированного персонала и недостаток желания что-то делать, ведь народ и так потребляется. И у меня есть сильное подозрение, что последний пункт он и есть ключевой в этой проблеме.
640 килобайт хватит всем.
Уильям Гейтс
Но если у меня возникло желание заполучить IPv6, то я его заполучу. И в этом нам поможет… Нет, не киножурнал «Хочу все знать!», хотя он точно не помешал бы. Разбираться в том, каким образом можно получить себе IPv6, если провайдер дает только IPv4 и то не с публичным («белым»), а с «серым» адресом, будем по официальным мануалам, постам в сетях и всём таком прочем.
Итак. Протокол IPv6 достаточно гибкий и одновременно сложный в понимании. Чем дальше заходит технология, тем больше времени нужно ей посвятить, чтобы понять каким образом реализовать тот или иной финтель. Если сравнивать IPv6 с IPv4, то последний раза в два проще, как минимум. Поэтому будем решать задачу пошагово, стараясь пройти от простого к сложному, получая в каждый момент времени удобоваримый результат.
IPv4 адресов вообще за глаза.
Уинтон Серф
Определим сеттинг. Имеется типовая локальная сеть, управляемая роутером Keenetic, в сети несколько машин и прочих устройств, а также домашний сервер под управлением Ubuntu. На VPS установлен и настроен WireGuard VPN. Провайдер интернет для локальной сети поставляет подключение к глобальной сети только по протоколу IPv4, более того, выдаваемый провайдером адрес относится к непубличному диапазону, он серый. Поэтому подключиться к этому серому адресу извне нельзя. Изнутри наружу можно выходить, снаружи внутрь нет. Все устройства в локальной сети находятся за так называемым NAT.
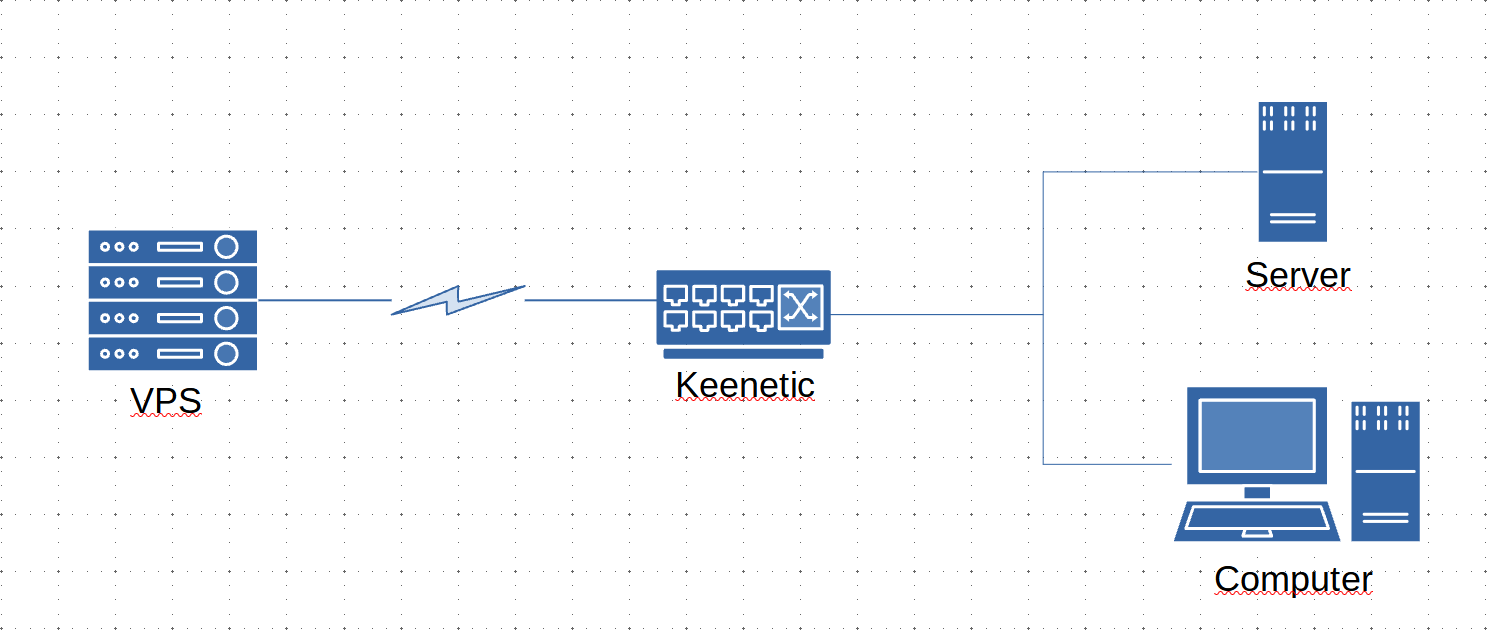
Типовая схема сети. Красным редактор услужливо подчеркнул все, что он не знает.
Если провайдер не выдает IPv6 адреса, то единственным способом получить IPv6 в настоящее время является туннелирование IPv6. Туннелирование возможно по протоколу 6in4 (не путать с 6to4), более того — создание такого туннеля есть штатная функция в современных Keenetic. Однако для того, чтобы заработало туннелирование, необходимо наличие белого IPv4 адреса. А их мало и их отнимают от тех, у кого они еще остались. А в нашем примере все находится за NAT и с одним единственным серым IPv4 адресом выдаваемом провайдером.
Что же делать в таком случае? Единственным вариантом, кроме как перейти на другого провайдера, является создание собственного туннеля для пробрасывания IPv6 протокола. Для этого в обязательном порядке требуется наличие VPS, благо их может приобрести любой желающий как услугу за весьма скромное вознаграждение. На VPS в обязательном порядке должно быть подключение к IPv6. Либо VPS без IPv6, тогда придется использовать тоннельного брокера IPv6 с протоколом 6in4. Либо потребуется найти туннельного брокера IPv6 который уже раздает IPv6, в этом случае VPS не потребуется.
Я постараюсь идти от простого к сложному, какие-то моменты буду разъяснять по ходу продвижения, поэтому рекомендую не перескакивать через разделы, а ознакомиться со всем материалом от начала и до самого конца. Сконцентрируемся на варианте с VPS, так как в этом случае все находится под контролем от и до, и есть возможность разобраться с вопросом досконально.
Получаем статический серый IPv6 адрес
Это самый простой вариант, который позволит получить IPv6 всего за несколько минут. Здесь и далее я буду подразумевать, что на серверах установлена операционная система Ubuntu версии не менее 18, а заодно установлен и работает WireGuard.
На VPS у нас есть какой-то публичный IPv6-адрес. В этом случае конфиг WireGuard на сервере следующий:
[Interface] Address = 10.66.67.1/24,fd42:42:43::1/64 ListenPort = 55520 PrivateKey = +…= PostUp = iptables -A FORWARD -i ens3 -o wg0 -j ACCEPT; iptables -A FORWARD -i wg0 -j ACCEPT; iptables -t nat -A POSTROUTING -o ens3 -j MASQUERADE; ip6tables -A FORWARD -i wg0 -j ACCEPT; ip6tables -t nat -A POSTROUTING -o ens3 -j MASQUERADE PostDown = iptables -D FORWARD -i ens3 -o wg0 -j ACCEPT; iptables -D FORWARD -i wg0 -j ACCEPT; iptables -t nat -D POSTROUTING -o ens3 -j MASQUERADE; ip6tables -D FORWARD -i wg0 -j ACCEPT; ip6tables -t nat -D POSTROUTING -o ens3 -j MASQUERADE ### Server [Peer] PublicKey = k…= PresharedKey = B…= AllowedIPs = 10.66.67.3/32,fd42:42:43::3/128 ### Computer [Peer] PublicKey = j…= PresharedKey = u…= AllowedIPs = 10.66.67.4/32,fd42:42:43::4/128
На VPS WireGuard создал две сети:
- 10.66.67.0/24 для IPv4 соединений.
- fd42:42:43::0/64 для IPv6 соединений.
Причем сеть fd42:42:43::0/64 является частной (в терминологии IPv6 — локальной), она недоступна извне и не маршрутизируется. Обратите внимание, что все ключи сокращены в целях обеспечения безопасности, а IP-адреса частично литерализованы. В конфиге добавлены сразу два пира. Server — конфиг для сервера Ubuntu в локальной сети, а Computer для «персоналки», опять же в локальной сети. Так же, в настройках конфига на VPS всем пирам сразу назначены unicast адреса, т.е. это адреса конечных устройств, об этом говорит префикс /128. А префикс /64 указывает на выделение целой подсети.
Но вернемся к конфигурации Server и Computer.
[Interface] PrivateKey = 0…= Address = 10.66.67.3/32,fd42:42:43::3/128 DNS = 1.1.1.1,8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= Endpoint = 185.x.x.x:55520 AllowedIPs = ::/0
Выше приведен конфиг для Server, какие мы здесь видим особенности? Первая — указан адрес пира как для IPv4, так и для IPv6 в виде unicast адреса, принадлежащего только одному устройству. А второе, это параметр AllowedIPs, в котором указано только ::/0. При запуске интерфейса WireGuard создает правила маршрутизации в соответствии с указанными адресами AllowedIPs. Все, что подпадает под адреса AllowedIPs будет отправлено в VPN-туннель. Параметр ::/0 обозначает, что все пакеты IPv6 следует отправлять в VPN-туннель. А пакеты IPv4 маршрутизируются традиционным образом на Keenetic, т.е. не маршрутизируются на сервере VPS.
На стороне Computer установлена операционная система Windows и фирменное приложение WireGuard. Конфиг в нем следующий:
[Interface] PrivateKey = 0…= Address = 10.66.67.3/32, fd42:42:43::3/128 DNS = 1.1.1.1, 8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= AllowedIPs = ::/1, 8000::/1 Endpoint = 185.x.x.x:55520
Он практически повторяет конфиг от Server за исключением настройки AllowedIPs, в ней казано два адреса ::/1, 8000::/1. Такая настройка означает, что все пакеты IPv6, за исключением пакетов локальных адресов будут отправляться в VPN-туннель, а локальные адреса будут маршрутизироваться традиционным путем через локальный Keenetic.
Обычно у каждого устройства, работающего с IPv6, есть локальный IPv6-адрес, начинающийся с fe80. По этому адресу к устройству можно обратиться в локальной сети. Но в случае AllowedIPs = ::/0 все IPv6 пакеты маршрутизируются в VPN-туннель, соответственно они никогда не достигают адресата, так как для конкретно этого адреса отсутствует рабочий маршрут, да и адрес сам по себе не маршрутизируемый по умолчанию. И здесь сразу возникает вопрос, будут ли маршрутизированы пакеты fe80 в туннель при указании ::/0 или нет. По идее не должны, так как fe80 в принципе не должны обрабатываться роутерами и обязаны оставаться в рамках одной сети (одного сегмента), но как поступит конкретный образчик программного обеспечения нужно проверять индивидуально. Лучше постараться избегать подобных ситуаций и давать более четкие указания, что и куда маршрутизировать. Разобраться с тем, что указывать в AllowedIPs можно при помощи калькулятора, на который я даю ссылку при каждом удобном случае.
Но, если нам требуется на компьютере с Windows такое же поведение, как и на Server, т.е. маршрутизировать все IPv6 в туннель, то в приложении есть отдельная галочка в настройках пира с названием Kill switch. Если ее включить, то AllowedIPs примет значение ::/0 и все пакеты IPv6 будут отправляться в VPN-туннель. Функция применяется для изоляции IPv6 адресного пространства на конкретном компьютере.
И что же в результате? А то, что на всех пирах, на Server и на Computer, IPv6 соединения во внешний мир работают! А как? А вот с этим мы разберемся в следующем разделе.
Однако, в данной конфигурации интернет по IPv6 хоть и работает, но с некоторыми оговорками. Поскольку у нас получился IPv6 NAT (как бы это не звучало странно, ведь всегда декларировалось, что никакого NAT в IPv6 нет, а оказывается, если хочется, то его можно соорудить), то несмотря на наличие IPv6 и прохождения всех тестов браузеры будут предпочитать IPv4. Почему? Потому, что браузер не любит серые IPv6 адреса (по крайней мере мой Yandex.Browser поступает именно так, а вот Edge сразу ушел на IPv6), второй фактор – если соединение на IPv4 открывается быстрее, то оно и будет использовано. И единственный способ, в указанной ситуации, открыть сайт по IPv6 — указать его домен с учетом IPv6 напрямую, если такой у него вообще присутствует. Например, ipv6.google.com. Но большинство сайтов включают оба протокола на одном домене и выбрать какой из вариантов использовать просто так нельзя.
Что означают параметры в PostUp и PostDown?
В параметрах PostUp и PostDown указываются команды, которые выполняются при активации интерфейса VPN и при его деактивировании соответственно. Можно указывать здесь любые команды в операционной системе, включая вызовы программ и скриптов. В приведенных выше примерах используется исключительно вызов Iptables. Iptables это такой файервол в Linux. Iptables предназначен для определения правил управления межсетевым экраном для пакетов IPv4 протокола, а ip6tables для IPv6. Нас интересует как раз второй, хотя все вызовы в настройках WireGuard у них одинаковые. Пройдемся по всем командам и попробуем узнать, что они делают. К слову, wg0 — интерфейс WireGuard, а ens3 — основной сетевой интерфейс на используемом VPS.
iptables -A FORWARD -i ens3 -o wg0 -j ACCEPT;
Команда добавляет (-A) действие по переадресации пакета далее (ACCEPT) в цепочку для маршрутизируемых пакетов (FORWARD) на входящем интерфейсе ens3 и выходящем интерфейсе wg0. Таблица, в которой добавляется действие в цепочку используется по умолчанию, т.е. таблица filter. Другим словами, все IPv4 пакеты приходящие с ens3 и с направлением в wg0 будут благополучно пропущены.
iptables -A FORWARD -i wg0 -j ACCEPT;
Команда добавляет действие по разрешению передачи пакетов с интерфейса wg0 на все остальные интерфейсы.
iptables -t nat -A POSTROUTING -o ens3 -j MASQUERADE;
Команда использует таблицу nat и записывает правило в цепочку, обрабатывающую пакеты после (POSTROUTING) прохождения всех предыдущих цепочек с выводом в интерфейс ens3. А применяемое действие заменяет адрес источника в пакете на адрес VPS при отправке его в интерфейс ens3. Т.е. происходит фактически установка NAT, все пакеты IPv4, которые приходят на интерфейс ens3 и уходят далее (в глобальную сеть или еще куда) «представляются» как пакеты отправленные с сетевого интерфейса esp3 VPS, т.е. самим VPS.
ip6tables -A FORWARD -i wg0 -j ACCEPT;
Производит аналогичное действие варианту для IPv4. Разрешает передачу пакетов с wg0 на все остальные интерфейсы.
ip6tables -t nat -A POSTROUTING -o ens3 -j MASQUERADE
Производит аналогичное действие варианту для IPv4. Создает NAT для приходящих IPv6 пакетов на интерфейс ens3.
Соответственно таблица filter для IPv4 выглядит следующим образом:
iptables -S -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT -A FORWARD -i ens3 -o wg0 -j ACCEPT -A FORWARD -i wg0 -j ACCEPT
Таблица nat для IPv4:
iptables -S -t nat -P PREROUTING ACCEPT -P INPUT ACCEPT -P OUTPUT ACCEPT -P POSTROUTING ACCEPT -A POSTROUTING -o ens3 -j MASQUERADE
Таблица filter для IPv6:
ip6tables -S -t filter -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT -A FORWARD -i wg0 -j ACCEPT
И таблица nat для IPv6:
ip6tables -S -t nat -P PREROUTING ACCEPT -P INPUT ACCEPT -P OUTPUT ACCEPT -P POSTROUTING ACCEPT -A POSTROUTING -o ens3 -j MASQUERADE
Глазастый читатель сразу заметил, что для IPv6 отсутствует цепочка FORWARD. Действительно, цепочка отсутствует в IPv6, а в IPv4 она есть. Данное правило добавлено в целях совместимости с разными дистрибутивами Linux и соответственно с разными настройками iptables по умолчанию. В IPv4 уже есть общая цепочка -P FORWARD ACCEPT используемая как действие, когда не подходят никакие другие цепочки. В секции IPv6 она тоже есть, но видимо, в некоторых дистрибутивах Linux это не всегда так и автор установщика WireGuard подстраховался, добавив дополнительную настройку.
Соответственно PostDown выполняет все те же команды, но в обратном порядке. В случае, если VPS незапланированно перезагрузится, ничего страшного не произойдет. Команды iptables подаваемые подобным образом существуют только до перезагрузки.
Со стороны Server ситуация с iptables проста. PostUp и PostDown в конфигурационном файле не прописаны, поэтому они не запускаются. Все iptables находятся в своем состоянии по умолчанию:
ip6tables -S -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT
А что происходит с маршрутизацией?
Для IPv4 маршрутизация на VPS незамысловата (со стороны VPS):
ip route default via 185.x.x.1 dev ens3 onlink 10.66.67.0/24 dev wg0 proto kernel scope link src 10.66.67.1 185.x.x.0/24 dev ens3 proto kernel scope link src 185.x.x.101
Маршрут по умолчанию для IPv4 пакетов отправляется на аплинк с адресом 185.x.x.1, т.е. все пакеты, которые не понятно куда отправлять будут отправлены на этот адрес, а дальше там все само найдет своего адресата или просто сгорит в бесконечной петле маршрутизации. Все пакеты для сети 10.66.67.0/24, а это сеть IPv4 внутри wg0, маршрутизируется с 10.66.67.1 на интерфейс wg0, это адрес самого WireGuard VPN-сервера на VSP. И третья строчка отправляет пакеты для сети 185.x.x.0/24 на интерфейс ens3 если отправитель 185.x.x.101, т.е. VPS, так как его адрес и есть 185.x.x.101.
Что означают все эти proto и kernel? Тут все просто:
- proto kernel — маршрут созданный ядром операционной системы при ее запуске.
- scope link — означает ограничение действия маршрута, в данном случае он ограничен только данным интерфейсом.
- src — указывает на адрес откуда должен прибыть пакет, который подпадет под указанное правило.
- onlink — означает прямое подключение к интерфейсу, без указания конкретного адреса.
Для IPv6 маршруты интереснее:
ip -6 route ::1 dev lo proto kernel metric 256 pref medium 2a04:xxxx:xxxx::/48 dev ens3 proto kernel metric 256 pref medium fd42:xxxx:xxxx::/64 dev wg0 proto kernel metric 256 pref medium fe80::/64 dev ens3 proto kernel metric 256 pref medium default via 2a04:xxxx:xxxx::1 dev ens3 metric 1024 onlink pref medium
В принципе, настройки маршрутизации в IPv6 совпадают с тем, что есть для IPv4, но появились дополнительные параметры, такие как metric и pref. Metric задает приоритет маршрута. В отличие от межсетевого экрана, при маршрутизации пакет отправляется по первому подходящему маршруту, поэтому тут важно настроить нужный приоритет, если есть потребность, например, отправлять пакеты из подсети в одно место, а пакеты конкретного хоста из этой подсети в совсем другое. Чем меньше значение параметра metric, тем больший приоритет имеет маршрут, и будет выполняться раньше. У параметра metric есть альяс preference. Задается значение 32-х битным числом. Параметр metric работает как для IPv4, так и для IPv6.
Параметр pref задает предпочтение по определению маршрутов посредством поиска роутеров по соответствующим линкам. Работает для пакетов IPv6 и бывает трех видов low (для низкого приоритета), medium (для среднего) и high (для высокого). Применяется для случаев, когда доступно сразу несколько роутеров.
Получаем статический белый IPv6 адрес. Вариант /64.
В предыдущем разделе я разобрал самый простой способ получить IPv6-адрес для локальной сети через VPN-туннель. Этот вариант подойдет и в случае, если провайдер, предоставляющий услуги VPS тоже козлина, зажал IPv6-адреса и выдал только /128 (единичный) адрес исключительно для VPS. Но в большинстве случаев IPv6-адресов выдается сразу целая горсть, например, /64 или /48. Рассмотрим случай, когда провайдер настроил все по инструкции на «Хабре» и выдал на VPS целую огромную подсеть /64, в которую можно поместить, наверное, все устройства в городе и еще останется.
Я немного поспешил стараясь с легкостью ворваться в бодрящий мир настоящего интернета с белым IPv6 адресом, но суровая реальность оказалась действительно суровой. Ни у одного моего VPS не было ни одной сети IPv6, которой я мог бы воспользоваться. Я не знаю истинных причин, почему провайдеры VPS не выдали на моих планах ни /48, ни даже /64 сети, а просто назначили всего 1 (один) IPv6 адрес каждому из моих VPS. Вероятно, что изюминка порылась в том, что за каждый дополнительный IPv4 адрес они берут дополнительную плату и за каждый дополнительный IPv6 адрес они тоже хотят взять дополнительную плату. Что уже вообще ни в какие ворота не лезет. Ребята, у вас там все нормально?
Ладно. Проблема получения сети IPv6 при наличии белого IPv4 решается банальным подключением к любому 6in4 тоннельному брокеру. Обычно они дают сеть /64, но можно получить и /48 без каких-либо проблем. Именно так я и поступил. В результате у меня появился новый интерфейс he-ipv6 (это интерфейс исключительно для IPv6 от туннельного брокера). IPv6 от провайдера VPS, дабы он не мешался под ногами (в моем случае применялось ручное конфигурирование IPv6 адреса на интерфейсе, поэтому был изменен файл /etc/network/intefaces) был отключен.
Чем плохо выделение разным клиентам адресов в рамках одной /64 сети (именно так поступают жадные провайдеры VPS)? А тем, что многие сетевые гиганты, полагают, что одному клиенту выдается /64 и если он там как-то набедокурил, например, рассылал спам в разные стороны, то ограничивать необходимо сразу всю сеть /64. Поэтому один недобросовестный клиент способен испортить жизнь всем остальным пользователям провайдера (хостера). А потом провайдеры еще удивляются, что мол такого, мы не знаем, почему вас банят везде.
При статичном и белом IPv4 можно использовать и вариант 6to4, но работает он несколько хуже, нежели туннельный вариант 6in4, так как все пакеты отправляются в ретранслятор пакетов между протоколами IPv6 и IPv4. Как правило, такой ретранслятор устанавливается у самого провайдера или где-то рядом, но выбрать какой именно ретранслятор (а их в сети может быть множество) используется нельзя. Поэтому, если что-то настроено не так как должно или же узел ретранслятора перегружен, то соединения будут так себе. Но у 6to4 есть и свое преимущество, пользователю IPv4 белого адреса сразу выделяется /48 сеть с 280 (это 2 в 80-й степени) IPv6 адресов.
Что бы все заработало, придется несколько поработать над настройками WireGuard. Я не просто так очень подробно разобрал все нюансы настроек и маршрутизации, так как вся магия выделения белых IPv6 адресов строится именно на них. Дополнительно я не буду модифицировать основной конфигурационный файл WireGuard созданный на предыдущем этапе, оставим его как работающий вариант, а создам новый, wg1 (в Ubuntu конфигурационный файлы WireGuard обыкновенно размещаются в /etc/wireguard). В таком случае эксперименты можно ставить параллельно работающему интерфейсу без опасения его повредить безвозвратно.
Итак, туннельный IPv6 брокер выделил мне 2001:xxx:xxx:xxx::/64 сеть на интерфейсе he-ipv6, где 2001:xxx:xxx:xxx::1 это адрес маршрута по умолчанию для IPv6 на интерфейсе he-ipv6, а 2001:xxx:xxx:xxx::2 адрес собственно VPS.
WireGuard конфигурационный файл wg1.conf:
[Interface] Address = 2001:xxxx:xxxx:xxxx::3/64 ListenPort = 55521 PrivateKey = +…= PostUp = ip -6 route del 2001:xxxx:xxxx:xxxx::/64 dev he-ipv6 PostDown = ip -6 route add 2001:xxxx:xxxx:xxxx::/64 dev he-ipv6 ### Client j1800 [Peer] PublicKey = k…= PresharedKey = B…= AllowedIPs = 2001:xxxx:xxxx:xxxx::/64
Дам пояснению по тем настройкам, что приведены в этом конфигурационном файле. Начнем с Address в блоке [Interface], здесь указан 2001:xxxx:xxxx:xxxx::3 адрес VPS машины в WireGuard туннеле на интерфейсе he-ipv6. Соответственно у нас :1 используется как маршрут по умолчанию, этот адрес находится с «той» стороны 6in4 туннеля, адрес :2 это адрес VPS на «этой» стороне 6in4 туннеля. И :3 это адрес VPS уже в интерфейсе wg1.

Распределение адресов между серверами
Прошу обратить внимание, что в wg1 используется другой порт (55521 против 55520) для установления подключений других пиров, таким образом у меня могут одновременно работать и wg0 и wg1 тоннели. Тут следует сразу обратить внимание, что wg0 прописывается скриптом установщиком для автоматического запуска при перезагрузке VPS. Аналогичное действие можно установить и для wg1 посредством следующей команды systemctl enable wg-quick@wg1.
В конфигурации wg1 у меня отсутствуют записи ip6tables в PostUp и в PostDown. Причина тому в изначальной конфигурации межсетевого экрана на VPS:
ip6tables -S -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT
Однако, их можно установить дополнительно, либо дописать в туже строчку через точку с запятой, либо просто новой строкой с PostUp/PostDown по аналогии с wg0 (конфигурационный файл допускает множественное указание PostUp/PostDown), только не используем NAT и MASQUERADE. Сразу обращаю внимание на то, что в конфигурационном файле у меня присутствуют только IPv6 настройки, так как туннелирование IPv4 меня в данном случае не интересуют.
Вместо настройки межсетевого экрана в PostUp и PostDown у меня присутствует удаление маршрута на выделенную туннельным брокером сеть при установлении туннеля wg1 (ip -6 route del 2001:xxxx:xxxx:xxxx::/64 dev he-ipv6) и ее обратное добавление при отключении туннеля. Операция крутая, но позволяет не прописывать маршруты, например, ip -6 route del 2001:xxxx:xxxx:xxxx::5/128 dev wg1, на каждого подключенного клиента. При удалении маршрута на сеть, если такой маршрут отсутствует, то команда ip ругнется и туннель не будет создан. В теории можно изобрести более сложную логику по удалению маршрута только в случае, если он есть, например, когда туннель от туннельного брокера создается медленнее, чем туннель WireGuard, но у меня работает и так, поэтому оставляю все в таком виде.
В результате таблица маршрутизации IPv6 адресов при работающем туннеле wg1 выглядит следующим образом:
ip -6 route show ::1 dev lo proto kernel metric 256 pref medium 2001:xxxx:xxxx:xxxx::1 dev he-ipv6 metric 1024 pref medium 2001:xxxx:xxxx:xxxx::/64 dev wg1 proto kernel metric 256 pref medium fe80::/64 dev ens3 proto kernel metric 256 pref medium fe80::/64 dev he-ipv6 proto kernel metric 256 pref medium default via 2001:xxxx:xxxx:xxxx::1 dev he-ipv6 metric 1024 onlink pref medium
В этом выводе я оставил в том числе и локальные IPv6 адреса, в дальнейшем буду стараться оставлять только то, что относится непосредственно к рассматриваемой теме. Кстати, fe80::/64 маршрутизируется на оба интерфейса, на ens3 и на he-ipv6, что очевидно не будет работать прямо вот так вот, пакет уйдет на ens3, так как он стоит в списке первым с тем же приоритетом, что и для he-ipv6. Если интерфейс ens3 будет недоступен, то пакет все равно не уйдет в he-ipv6, так как ens3 это единственный выход наружу для моей VPS и если он не работает, то и туннель к туннельному брокеру не поднимется. Обращу внимание на наличие маршрута 2001:xxxx:xxxx:xxxx::/64 dev wg1. Он был создан автоматически WireGuard при создании туннеля wg1 по настройке AllowedIPs единственного пира.
На стороне клиента конфигурационный файл wg1.conf свой собственный и содержит он следующее:
[Interface] PrivateKey = 0…= Address = 2001:xxxx:xxxx:xxxx::5/64 DNS = 1.1.1.1,8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= Endpoint = 185.xxx.xxx.xxx:55521 AllowedIPs = ::/1,8000::/1
Собственно, в блоке [Interface] мы указываем адрес :5, который мы назначаем нашему клиенту, а именно машине с Ubuntu. Назначается он в ручном режиме. В блоке [Peer] указываем данные нашего VPS, не забывая, что у нас поменялся номер порта. Ключи я не генерировал новые, взял от wg0, как в случае конфигурационного файла на VPS, так и для компьютера с Ubuntu. Некоторый интерес вызывает AllowedIPs = ::/1,8000::/1. Настройка состоит из двух диапазонов адресов, а не одного, как было в wg0. Такое определение настройки позволяет оставить только маршрутизируемые адреса для отправки в туннель 6in4.
В качестве альтернативы в плане отключения маршрутизации для интерфейса he-ipv6 можно изменить метрику для маршрута. Чем меньше значение метрики, тем больший приоритет у данного маршрута. WireGuard устанавливает метрику маршрута равной в 256 единиц (по крайней мере у меня так), соответственно достаточно единоразово изменить маршрут 2001:xxxx:xxxx:xxxx::/64 dev he-ipv6 proto kernel metric 256 pref medium на маршрут с большей метрикой. Если в вашей конфигурации маршрутов метрика у WireGuard выше, чем у туннельного интерфейса, то вообще ничего делать не нужно.
Как в таком случае подключить другие машины в сети за IPv4 NAT? Аналогичным образом, как и в случае wg0, просто создаем новый туннель с компьютера, которому требуется выход в глобальную сеть по протоколу IPv6, к VPS посредством WIreGaurd.
Как понять, что провайдер VPS водит за нос с IPv6?
Самый простой способ – спросить в службе поддержки провайдера. Они обязаны знать о том, выделяется ли один IPv6 адрес (не сеть) на VPS или же выделяется сеть, и если сеть, то какая именно.
Способ слегка сложнее, но у меня он работает. Добавить еще один IPv6 адрес на существующий интерфейс из предполагаемого адресного пространства, которое должно быть доступно выбранной VPS. Проделать манипуляцию можно прямо из консоли:
ip address add 2001:xxxx:xxxx:xxxx:yyyy::5/64 dev ens3
В этом примере я добавил новый адрес из подсети, которая должна быть доступна, если провайдер выделил префикс /64 на VPS, к интерфейсу ens3. Если подобные фокусы возбраняются, то интерфейс IPv6 перестает функционировать в сторону интернет. После удаления дополнительного адреса работоспособность восстанавливается.
Получаем статический белый IPv6 адрес. Варианты /48, /64 из /48 и /72 из /64.
В принципе, дальнейшее размножение туннелей WireGuard с разными префиксами делается по аналогии с вариантом /64, но тут есть некоторые нюансы. Начнем с сети /48, которую я получил от туннельного брокера по туннелю 6in4 в добавок к /64 сети. Адресные пространства этих двух сетей частично пересекаются: 2001:0470:yyyy:xxxx::/64 и 2001:0470:yyyy::::/48. Обе сети являются маршрутизируемыми со стороны HE, а как иначе-то? Но сеть /48 маршрутизируется на выделенный IPv6 адрес в сети /64. Предполагается, что устройство с /64 сетью и адресом будет выступать в качестве маршрутизатора для всех адресов сети /48.
В сеть /48 можно поместить, наверное, все устройства, подключающиеся в мире к сети, и еще останется. Подсеть /48 является стандартом на выделение префикса (подсети) для «конечного» пользователя, не важно, кто он обычный «физик» или «юрик». Сеть /48 содержит 65 тысяч сетей /64, а каждая сеть /64 допускает подключение … хм … в общем очень большого количества устройств. Очень. Более того, сеть /64 является принятым минимумом для выделения подсети кому-либо вообще. Нет, конечно, никто не запрещает выделить сеть /120, с номерной емкостью всего в 256 адресов, но это уже будет официально считаться жлобством и нарушением всех договоренностей.
Итак, туннельный брокер выделил на мой VPS подсеть /48 и /64, соответственно я могу спокойно выделить для моей локальной сети за IPv4 NAT все адресное пространство /48. Напомню, что вся сеть /48 маршрутизируется на стороне HE на IPv6 адрес, который назначен конечной точкой 6in4 туннеля, т.е. моему VPS-серверу. Маршрутизация между /64 сетью и /48 сетью поднимается силами WireGuard. Конфигурационные файлы следующие:
#From HE /48 [Interface] #Address = 2001:470:xxxx::/48 Address = 2001:470:xxxx:xxxx::15/64 ListenPort = 55522 PrivateKey = +…= ### Client [Peer] PublicKey = k…= PresharedKey = B…= AllowedIPs = 2001:470:xxxx::/48
Конфигурационный файл совершенно обычный, нюанс кроется в адресе серверной части. Как видно, адрес сервера можно выдать как в сети /48 (закомментировано), а можно выдать его в сети /64 и отдать полностью всю сеть /48 в туннель.
#From HE /48 [Interface] PrivateKey = 0…= Address = 2001:470:xxxx::5/48 DNS = 1.1.1.1,8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= Endpoint = 185.xxx.xxx.xxx:55522 AllowedIPs = ::/1,8000::/1
Конфигурационный файл со стороны клиента — типичный. Адрес :5 в /48 сети назначен руками.
Но, что если не хочется полностью всю сеть /48 отправлять в туннель для жалкой двадцатки адресов? Не проблема, от /48 можно отрезать столько, сколько нужно. Например, /64 сеть. Конфигурация на стороне VPS-сервера:
#From HE /48-64 [Interface] Address = 2001:470:xxxx::/48 ListenPort = 55523 PrivateKey = +…= ### Client [Peer] PublicKey = k…= PresharedKey = B…= AllowedIPs = 2001:470:xxxx:1::/64
Здесь я уже использую IPv6 адрес для «серверного» адреса из /48 сети, но той части, которая не подпадает под адресацию выделенной /64 сети. Да, 2001:470:xxxx::/48 такое выделение адреса означает, что выделен адрес :0, что в IPv6 является вполне работоспособным адресом, в противовес IPv4, где .0 считается недопустимым адресом для хоста. И конфигурация со стороны конечной точки WireGuard туннеля:
#From HE /48-64 [Interface] PrivateKey = 0…= Address = 2001:470:xxxx:1::5/64 DNS = 1.1.1.1,8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= Endpoint = 185.xxx.xxx.xxx:55523 AllowedIPs = ::/1,8000::/1
Схема полностью аналогична предыдущей. А что, если у нас нет возможности получить сеть /48, провайдер-жадюга выделил только /64 сеть, но хочется ее раздать прям в несколько мест. В этом случае /64 придется порезать на более мелкие кусочки. При разделении сети можно увеличивать префикс на единичку плоть до /127 (/128 это уже единичный адрес). Но существует негласное правило предписывающее идти в сторону уменьшения полубайтом, т.е. 4 битами. Весь IPv6 адрес состоит из 128 бит, сеть /64 есть ровно половина всего адреса. Соответственно прибавляя по 4 к префиксу, происходит движение в сторону уменьшения подсети. Иными словами, рекомендуется двигаться в следующей последовательности /64, /68, /72, /76 и т.п. Данная рекомендация существует исключительно для удобства сетевых администраторов для манипуляций с адресами, т.к. в этом случае человек будет оперировать с 16-ричной цифрой целиком, а не только ее частью. Компьютерам же, очевидно, это правило не нужно.
В конфигурационных файлах ниже я взял сеть /72 и «откусил» ее сети /64 что выдал мне брокер. Конфигурация сервера:
#From HE /64-72 [Interface] Address = 2001:470:xxxx:xxxx:100::3/72 ListenPort = 55524 PrivateKey = +…= ### Client [Peer] PublicKey = k…= PresharedKey = B…= AllowedIPs = 2001:470:xxxx:xxxx:100::/72
В этом случае я назначил адрес сервера из того же пула, что и выдается всем пирам. Конфигурация клиента:
#From HE /64-72 [Interface] PrivateKey = 0…= Address = 2001:470:xxxx:xxxx:100::1/72 DNS = 1.1.1.1,8.8.8.8 [Peer] PublicKey = j…= PresharedKey = B…= Endpoint = 185.xxx.xxx.xxx:55524 AllowedIPs = ::/1,8000::/1
Подключение всех клиентов осуществляется по ранее рассмотренной схеме с установкой WireGuard на все компьютеры. Но можно использовать и единственное WireGuard подключение, например, на домашнем сервере или роутере, далее прописать адреса раздаваемой сети на всех компьютерах и устройствах в IPv4 NAT сети и, опять же руками, настроить на них маршрут по умолчанию на конечную точку WireGuard. Но это не совсем удобно, а на некоторых устройствах, например, смартфонах и не всегда возможно. Поэтому далее постараемся разобраться каким образом получить автоматическое конфигурирование адресов IPv6 в сети за туннелем. Обратите внимание на некоторые нюансы написания IPv6 адресов, например, адрес 2001:470:xxxx:xxxx:100::1, где 470 и 100 на самом деле являются 0470 и 0100, просто при записи IPv6 адреса допускается опускание лидирующих нулей или целиком кусочка адреса, если в нем только одни нули.
Автоконфигурирование IPv6 адреса в конце туннеля
Одной из особенностей IPv6 является то, что протокол весьма гибок в плане автоматического построения маршрутизации и получения адресов. В IPv6 для этих целей можно задействовать как минимум следующие средства Neighbor Discovery (ND), Stateless Address Auto-Configuration (SLAAC) и DHCPv6. Пробежимся по ним и постараемся понять, что можно применить в нашем случае.
Neighbor Discovery
«Протокол обнаружения соседей» является ключевой технологией IPv6. При помощи ND происходит общение всех узлов в рамках одного сегмента (L2 по OSI) посредством использования специальных широковещательных групповых адресов (L3). При помощи ND, в том числе, происходит и автоконфигурирование узлов, определяются дубликаты IPv6 адресов, выясняются адреса роутеров, метрики канала и прочее. Вся «магия» ND заключается в сообщениях нескольких типов, которые передаются между узлами:
Router Solicitation (RS) — запрос маршрутизаторов. При включении интерфейса, например, при загрузке ПК, компьютер выдает в сеть запрос типа RS. Все роутеры в сети, получив RS-запрос, обязаны на него незамедлительно ответить своим RA-ответом. Маршрутизаторы периодически самостоятельно выдают в сеть RA-пакеты, а RS и придумано специально, если не хочется ждать. Запрос отправляется на адрес FF02::2, являющимся общим адресом для всех маршрутизаторов IPv6, в рамках одного сегмента.
Router Advertisement (RA) — анонсирование маршрутизатора. Пакет данного типа отправляется каждым роутером в сеть с заданным интервалом либо как ответ на RS-запрос. RA-пакет объявляет, что в сети есть роутер, вот он. В RA-пакете содержится информация о префиксе сети, так определяется, что и компьютер, и роутер вообще принадлежат одной сети (on-link) и прочая конфигурационная информация. RA-пакеты отправляются на адрес FF02::1, являющимся общим адресом для всех устройств в сети IPv6, разумеется, только в пределах одного сегмента. На основе RA-пакета устройство получает глобальный IPv6 (или не маршрутизируемый IPv6 адрес), а заодно понимает, куда именно отправлять пакеты, чтобы они уходили в безбрежный океан нулей и единиц.
Neighbor Solicitation (NS) — запрос соседей. Запрос применяется в первую очередь для определения Link-Local (FE80::) адресов всех устройств находящихся в одном сегменте (L2, т.е. получают не только IPv6 адреса соседей, но и их MAC-адреса, если сеть Ethernet). Этот же тип пакетов применяется и для определения дубликатов сетевых (L3, т.е. IPv6) адресов.
Neighbor Advertisement (NA) — анонсирования соседа. NA-пакет является ответом на NS-запрос. Но может быть сгенерирован и самостоятельно, например, в случае смены Link-Local адреса.
Redirect — переадресация. Такие пакеты генерируют маршрутизаторы для объявления приоритетного маршрутизатора.
Основываясь на ND можно получить некоторую информацию о том, что есть в сети. Для начала получим список всех IPv6 устройств, что сейчас находятся в сети:
ping -6 -w 1 ff02::1%enp3s0 PING ff02::1%enp3s0(ff02::1%enp3s0) 56 data bytes 64 bytes from fe80::aaa1:59ff:fe19:103f%enp3s0: icmp_seq=1 ttl=64 time=0.104 ms 64 bytes from fe80::b6a3:82ff:fe01:d00e%enp3s0: icmp_seq=1 ttl=64 time=0.517 ms (DUP!) 64 bytes from fe80::52ff:20ff:fe18:dd5e%enp3s0: icmp_seq=1 ttl=64 time=0.673 ms (DUP!) 64 bytes from fe80::52ff:20ff:fe13:3f5e%enp3s0: icmp_seq=1 ttl=64 time=0.674 ms (DUP!) 64 bytes from fe80::52ff:20ff:fe56:fd1a%enp3s0: icmp_seq=1 ttl=64 time=0.803 ms (DUP!) 64 bytes from fe80::200:1bff:fe18:bd56%enp3s0: icmp_seq=1 ttl=64 time=1.02 ms (DUP!) --- ff02::1%enp3s0 ping statistics --- 1 packets transmitted, 1 received, +5 duplicates, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.104/0.632/1.024/0.282 ms
Для общей переклички необходимо «пропинговать» специальный адрес ff02::1, иначе мы имитировали запрос NS (и в утилите ping, и в ND используются ICMP-запросы).
Немного информации по параметрам использованным вместе с ping: -6 дает указание на использование IPv6, -w 1 ограничивает время проверки только 1 секундой, при интервале между запросами в 1 секунду, мы опросим все узлы в сегменте только 1 раз. %enp3s0 после адреса указывает какой именно интерфейс использовать для отправки ICMP6-запросов (без указания интерфейса утилита не будет знать через какой интерфейс проводить процедуру, так как IPv6 адресов может быть несколько, впрочем как и интерфейсов, сетевых карт).
ping -6 -w 1 ff02::1%wg48 PING ff02::1%wg48(ff02::1%wg48) 56 data bytes 64 bytes from 2001:470:xxxx::5: icmp_seq=1 ttl=64 time=0.119 ms 64 bytes from 2001:470:xxxx:xxxx::15: icmp_seq=1 ttl=64 time=24.9 ms (DUP!) --- ff02::1%wg48 ping statistics --- 1 packets transmitted, 1 received, +1 duplicates, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.119/12.519/24.919/12.400 ms
В первом примере вывода был использован интерфейс физической сетевой карты моего Ubuntu-сервера, соответственно в сети помимо самого сервера (первый ответ) присутствует еще 5 IPv6 устройств с указанными локальными адресами. Значение DUP! в скобках, в данном случае не означает задвоение IPv6 адреса, так как на один ICMP6 запрос были получены ответы от всех устройств, поэтому они и пометились как дублирующие. Во втором примере я выполнил аналогичный запрос, но с указанием интерфейса wg48, вариант с туннелированием /48 сети в туннель WireGuard. Как видно, откликнулось всего два адреса, адрес VPS-сервера (:15) и адрес моего Ubuntu-сервера (:5).
Альтернативно можно посмотреть соседей через команду ip -6 neigh show (для совсем ленивых ip -6 n) или netsh interface ipv6 show neighbors в Windows.
К сожалению, мне так и не удалось успешно запустить ping с указанием групповых адресов под Windows, хотя команда должна быть следующей ping ff02::1%7, где %7 указывает на интерфейс, через который Windows подключается к сети. Интерфейс же можно выяснить через команду ipconfig /all. Интерфейс проставляется у Link-local адресов. В сети есть свидетельства, что данная функция в Windows не вполне работоспособна.
Помимо ff02::1 можно послать запрос на другой групповой адрес ff02::2, ответить на него должны все роутеры. Помимо указанных выше специальных групповых (Multicast) адресов существует их еще некоторое количество, но с ними лучше ознакомиться в официальной документации.
ND Proxy
Продолжая тему жадности провайдеров, а точнее проблем, которые могут появиться у их клиентов, если провайдер либо слишком жаден, либо не совсем компетентен в сетях IPv6. Наиболее типичный сценарий следующий, он же встречается и при использовании VPS. Провайдер выдает клиенту какую-то сеть IPv6, размер ее не так важен. Выдает ее с маршрутизацией на стороне своего роутера. Таким образом, все устройства клиента маршрутизируются исключительно роутером провайдера и для нормальной их работы они должны находиться в одном сегменте с роутером. Как мы знаем, в рамках одного сегмента хосты взаимодействуют друг с другом посредством Link-local адресов, соответственно находят друг друга через ND.
Проблема начинается тогда, когда клиент хочет поделить сеть, которую ему выдал провайдер. И отдать часть адресов, например, другой своей локации через применение туннелирования или же изолировать отдельные машины в своей сети на другом интерфейсе. К примеру, многие отделяют пользовательское оборудование: ноутбуки, смартфоны и планшеты, от остального оборудования (серверов, камер видеонаблюдения и так далее). Причины для подобного деления очевидны. А в случае VPS у клиента может возникнуть задача передать часть адресов посредством туннеля еще куда-то, ведь потребности клиентов неисповедимы. И тут происходит конфуз.
Он связан с тем, что выделенные в другие сегменты, на другие интерфейсы адреса, перестают маршрутизироваться роутером провайдера. Грубо говоря, IPv6 на них есть, но он не работает. Почему так произошло? Потому что ND со стороны сегмента с маршрутизатором банально не видит ND со стороны другого сегмента или интерфейса. А если не видит, то для провайдерского роутера их не существует, они вне сети. И он вроде бы понимает, что пакеты пришедшие извне к этим адресам они должны быть отправлены получателям тут же, но получателей нет в его поле видимости. А доступа к провайдерскому роутеру, чтобы настроить там верную маршрутизацию к выделенным адресам, нет.
Один из правильных вариантов решения данной проблемы кроется в назначении гейтвея по умолчанию для всей сети на стороне роутера, который будет использоваться, если роутер не видит по ND эти адреса (если видит, то будет отправлять им пакеты напрямую). Разумеется, на назначенном гейтвее необходимо настроить маршрутизацию в соответствии с делением на сегменты и/или интерфейсы, но это уже забота того, кто и производил деление.
В случае, когда нет возможности управлять провайдерским маршрутизатором поможет проксирование ND, которое позволит обеспечить связанность Link-local адресов и, как следствие, возможность автоматического конфигурирования IPv6 адресов в рамках выделенного префикса. Для целей проксирования ND существует два механизма:
- proxy_ndp — для случаев когда необходимо проксировать единичные адреса.
- NDP Proxy Daemon (ndppd) — когда требуется запроксировать целые сети.
В Ubuntu proxy_ndp уже встроена в систему, остается ее только включить и настроить.
Для включения функции необходимо внести следующую строку в /etc/sysctl.conf:
net.ipv6.conf.all.proxy_ndp = 1
Затем произвести перечтение конфигурации через sysctl -p. Либо ввести команду sysctl -w net.ipv6.conf.all.proxy_ndp=1 (в этом случае настройка применится сразу же, но она не сохранится после перезагрузки).
Затем необходимо добавить IPv6 адрес, который необходимо запроксировать, с указанием интерфейса, на котором он будет присутствовать в виде виртуального запроксированного адреса:
ip -6 ne add proxy 2a04:xxxx:xxxx:xxxx::1 dev ens3
Необходимо запомнить, что данная настройка прокси будет работать только до перезагрузки хоста. Поэтому, если требуется постоянное присутствие прокси, то необходимо внести настройку в скрипты автозагрузки или же в настройки того же WireGuard. Костыль, конечно, но работает.
Stateless Address Auto-Configuration
Исходя из названия, не трудно догадаться, что SLAAC предназначен для упрощенного, автоматического (в противовес ручному назначению) присвоения IPv6 адресов устройствам. Stateless здесь означает, что назначенный устройству адрес никем централизованно не хранится и есть вероятность, что через некоторое время этот адрес может получить другое устройство. Назначение дублирующих адресов блокируется через механизмы ND. Дополнительно SLAAC не сообщает хостам адреса DNS-серверов, поэтому их следует задавать самостоятельно или же получать адреса через другой механизм, например, от DHCP-сервера от IPv4 сети.
SLAAC нацелен на получение IPv6 адресов отличных от адресов для использования внутри сегмента, т.е. Link-local адресов. С этой задачей отлично справляется ND. SLAAC позволяет получать глобальные (или частные) IPv6 адреса от роутеров. Но для этого он всецело полагается на ND. Упрощенно процедура по получению глобального IPv6 адреса выглядит следующим образом:
- Получить не задвоенный Link-local адрес (FE80::/10) через ND.
- Послать запрос RS.
- Получить ответ RA. Сформировать маршрут по умолчанию на Link-local адрес откликнувшегося роутера.
- Сформировать на стороне хоста, самостоятельно, глобальный IPv6 адрес (обычно он состоит из префикса, полученного от роутера, и уникального идентификатора интерфейса, который может вычисляется по его MAC-адресу).
- Проверить сформированный адрес на предмет задвоения через ND.
- Начать пользоваться глобальным IPv6 адресом.
Выглядит все достаточно просто, за исключением того, что уникальный идентификатор в формате EUI-64, основанный на MAC-адресе позволяет четко отслеживать устройство при использовании внешних сервисов. И даже поменяв IPv6 префикс на совершенно другой, избавиться от привязки будет нельзя, все равно по MAC-адресу можно выявить устройство. Все это означает довольно серьезную дыру в прайваси. Посещение любых сервисов, любых веб-сайтов, позволит четко проследить за тем, каким именно устройством происходили подключения, так как предполагается, что MAC-адреса у всех устройств уникальны. В некоторых операционных системах вместо MAC-адреса используется случайный идентификатор, например, в Windows (работает начиная с Windows Vista), а вот в Ubuntu, даже 20-й версии, все еще присутствует MAC-адрес в IPv6 адресе по умолчанию. Что, конечно же на руку товарищу майору, но вызывает беспокойство у прогрессивной части человечества. Отслеживать с IPv4 NAT, особенно у крупных провайдеров, куда сложнее, чем с глобальными и привязанными к железу IPv6 адресами.
Что с этим делать? На самом деле тут целых 4 пути:
- Не использовать автоконфигурацию IPv6 адреса, а задавать его руками.
- Использовать временные IPv6 адреса, которые будут генерироваться каждую перезагрузку устройства (инициализацию интерфейса). Способ не подходит, если требуется обрабатывать входящие соединения по IPv6, так как адрес все время будет разный.
- Использовать заранее заданный статичный хэш, вместо MAC-адреса. Такой вариант подойдет, если не нужна привязка к MAC-адресу, но нужно обрабатывать входящие подключения, адрес будет оставаться (или по крайней мере его часть, при смене префикса) отслеживаемым.
- Использовать несколько, как минимум 2 IPv6 адреса. Один динамический, обновляется периодически. Он используется для выхода наружу. Второй статический, постоянно находится на машине и применяется для приема входящих подключений по IPv6.
Какой из способов наилучший — зависит от конкретной ситуации и доступной реализации.
DHCPv6
DHCPv6 сервер, как не трудно догадаться, является развитием обычного DHCP-сервера для работы с IPv6 протоколом. Основным отличием DHCPv6 от SLAAC является то, что DHCP выдает хосту адреса DNS-серверов для конвертации мнемонических адресов типа blog.kvv213.com в IP-адреса, а еще запоминает какой IP-адрес был выдан той или иной машине и выдает его повторно.
Как и SLAAC DHCPv6 нацелен на получение IPv6 адресов отличных от адресов для использования внутри сегмента (Link-local адресов). DHCPv6 позволяет получать глобальные (или частные) IPv6 адреса от роутеров. Но для этого он всецело полагается на ND, впрочем, в плане получения адресов в IPv6 все полагается на ND и ICMPv6. Упрощенно процедура по получению глобального IPv6 адреса при помощи DHCPv6 выглядит следующим образом:
- Получить не дублированный Link-local адрес (FE80::/10) через ND.
- Послать запрос RS.
- Получить ответ RA.
- Если полученный RA содержит указание на то, что у этого роутера есть DHCP, то сформировать DHCP-запрос и получить IPv6 адрес.
- Если ни в одном RA не оказалось признака наличия DHCP, то получить Link-local адрес DHCP посредством ICMP-запроса на групповой адрес ff02::1:2. По запросу на этот адрес откликаются DHCP-сервера. DHCP-сервер может быть установлен отдельно от маршрутизатора. Если DHCP обнаружен, послать DHCP-запрос, получить IPv6 адрес. Если же и тут пусто, то пользоваться SLAAC или сидеть без IPv6 адреса.
Использовать SLAAC, SLAAC + DHCPv6 или же полагаться только на DHCPv6 зависит от сообщения RA. В случае SLAAC+DHCPv6 хост получит IPv6 адрес от SLAAC, а все остальное от DHCPv6.
Пример запроса на ff02::1:2 с целью поиска DHCP:
ping -6 -w 1 ff02::1:2%enp3s0 PING ff02::1:2%enp3s0(ff02::1:2%enp3s0) 56 data bytes 64 bytes from fe80::52ff:20ff:fe18:dd5e%enp3s0: icmp_seq=1 ttl=64 time=0.606 ms 64 bytes from fe80::52ff:20ff:fe13:3f5e%enp3s0: icmp_seq=1 ttl=64 time=0.607 ms (DUP!) 64 bytes from fe80::52ff:20ff:fe56:fd1a%enp3s0: icmp_seq=1 ttl=64 time=0.731 ms (DUP!) --- ff02::1:2%enp3s0 ping statistics --- 1 packets transmitted, 1 received, +2 duplicates, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.606/0.648/0.731/0.058 ms
Запрос к адресу ff02::1:2 позволяет выявить все DHCP6 сервера. В выводе выше в моей локальной NAT «IPv4» сети обнаружилось целых три DHCP6 сервера. Это три роутера Keenetic трудящиеся в режиме Wi-Fi-системы. И кстати, все их Link-local IPv6 адреса сформированы с применением MAC-адресов.
Проблематика сетей меньше /64
Изучая различные статьи многочисленных авторов в отношении IPv6 я несколько раз наткнулся на смелые утверждения, что SLAAC не работает на сетях меньше /64. Более того, в таких сетях не работает и ND, а вероятно, что от того и не работает SLAAC. Более того, авторы приводят такой аргумент в свою поддержку, мол именно по этой причине решено выделять на каждого пользователя не меньше /64 префикса. Тут хочу сделать оговорку, для меня «меньшая» сеть означает, что в ней меньшее количество адресов. Так сеть /72 меньше сети /64, хотя 72 вроде, как и больше 64.
Ну, что же. Попробуем разобраться. Начнем с ND. ND это протокол, который обеспечивает принципиальную работоспособность IPv6. Он может не работать в случае, если системный администратор, взял и выпилил поддержку ICMPv6. Тогда ND работать не будет. Не будут работать автоматический поиск маршрутизатора, поиск дубликатов адресов, выделение Link-local и глобальных адресов в автоматическом режиме. Если не работает ND, то вся автоматика, основанная на нем, аналогично работать не будет, что очевидно. С другой стороны, ND нам нужен в первую очередь для получения Link-local адреса, который, на минуточку, относится к /10 сети. И в случае, если устройство находится само по себе в вакууме, без подключений к другим устройствам по IPv6 вообще, то и в этом случае ND будет работать, только подсоединяться ему будет не к кому. Поэтому утверждения по неработоспособность ND в сетях меньшего размера, чем /64 очень и очень спорное, хотя и отражено (без фактического объяснения) в RFC 5375 от 2008 года. Наиболее вероятное этому разъяснение кроется исключительно в административных ограничениях и конкретных реализациях протокола IPv6 конкретными производителями.
А вот со SLAAC все намного проще. Для автоматического назначения IPv6 адреса, глобального или частного, применятся генерирование адреса с использованием уникального идентификатора EUI-64, который имеет длину 64 бита и состоит либо из преобразованного MAC-адреса (длина 48 бит), либо полученного иным способом. И вот эти 64 бита необходимо присовокупить к выделенному префиксу. И если префикс меньше, чем /64, например, /72, то в этом случае для идентификатора из 64 бит просто не остается места и автоматическое выделение IPv6 адреса просто невозможно, по крайней мере по тому алгоритму, что реализован в SLAAC. И все. Никаких заговоров и теневого правительства.
Поднимаем автоконфигурацию SLAAC
Итак, получать сети IPv6 через WireGuard на свой сервер уже получается. Осталось только раздавать полученное в локальную сеть. В данном примере на мой сервер Ubuntu пробрасывается /48 сеть. Из нее я хочу раздавать в локальную сеть /64 префикс, тогда SLAAC будет работать. Для использования функции актоконфигурирования адресов на машинах в сети необходимо как-то анонсировать присутствие новой точки обмена трафиком по протоколу IPv6. Все дальнейшие операции производим на Ubuntu-сервере в локальной сети.
Анонсирование под Ubuntu осуществляет демон radvd. Устанавливается он традиционным для Ubuntu способом, но для того, чтобы он заработал, необходимо произвести некоторые настройки в системе.
Первое что необходимо включить пересылку IPv6 пакетов между интерфейсами. Пересылка включается в /etc/sysctl.conf путем раскоментирования или добавления следующих строчек (хотя можно ограничиться и только первой):
net.ipv6.conf.all.forwarding=1
net.ipv6.conf.default.forwarding=1
Данные настройки означают разрешение пересылки пакетов IPv6 между интерфейсами, всеми интерфейсами. После включения пересылки пакетов, сервер перестает быть восприимчивым к пакетам RA. Другими словами он сам не сможет сконфигурировать себе IPv6 адрес из предлагаемого префикса в рассылках RA. Это может привести, например, к проблеме получения IPv6 адреса от другого маршрутизатора, например, от uplink-а. В сети IPv6 может быть несколько маршрутизаторов и это нормально. Параметр пересылки пакетов включается при запуске WireGuard (если он устанавливался скриптом), однако, если radvd стартует ранее, то лучше иметь эти параметры включенными и соответственно прописанными в конфигурационном файле sysctl.conf.
Если необходимо, чтобы сам Ubuntu-сервер-маршрутизатор получал и обрабатывал RA-пакеты, то стоит в том же /etc/sysctl.conf «включить» следующую настройку:
net.ipv6.conf.interface.accept_ra = 2
Здесь вместо interface необходимо указать название того интерфейса, где все же необходимо обрабатывать RA при включенной пересылке пакетов (по сути, режим маршрутизатора). Альтернативным способом, можно прописать статический IPv6 адрес на основном сетевом интерфейсе в ручном режиме.
sudo systemctl enable wg-quick@wg0
sudo systemctl start wg-quick@wg0
Данными командами можно включить автозагрузку и запустить туннель WireGuard с именем конфигурационного файла wg0. Система должна работать автоматически и все операции должны возобновляться после перезапуска сервера.
После установки radvd и прописывания опций по пересылке пакетов необходимо настроить конфигурационный файл radvd, при установке пакета он сразу пытается загрузиться, а если конфигурационного файла нет, то запуск терпит неудачу с кучей красных надписей. Располагается конфигурационный файл он по адресу /etc/radvd.conf. В моем случае содержимое у файла следующее:
interface enp3s0
{
AdvSendAdvert on;
MaxRtrAdvInterval 300;
prefix 2a06:XXXX:XXXX:8::/64
{
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr off;
AdvValidLifetime 21600;
AdvPreferredLifetime 120;
};
RDNSS 2606:4700:4700::1111 2606:4700:4700::1001 2001:4860:4860::8888 {
};
};
Список опций минимален, но достаточен для нормальной работы сервера и назначения адресов страждущим клиентам. Для этой локальной сети по WireGuard я получаю 2a06:XXXX:XXXX:::/48 сеть. Из нее я выделю подсеть 2a06:XXXX:XXXX:8::/64, в рамках которой и будут назначаться адреса хостам в локальной сети. Первой строчкой идет привязка демона к интерфейсу. В моем случае это enp3s0. Второй группой идет объявление префикса для раздачи машинам в сети. И третьей группой идет объявление IPv6 DNS-серверов через пробел, а в фигурных скобках можно указать дополнительные параметры. В данном случае указаны DNS-сервера Cloudflare и Google. Выше по тексту упоминалось, что через RA-пакеты нельзя указать клиентам какие DNS-сервера использовать и это было основным недостатком SLAAC, но позже эту возможность допилили, и у DHCPv6, по факту, осталось не так много преимуществ.
Некоторые пользователи дополнительно устанавливают свой DNS-сервер на свой сервер. Но сейчас подобное уже не имеет смысла, так как подключения к сети нынче довольно быстрые, а удаленные сервера отвечают шустро. Плюс сами клиенты научились кэшировать ответы DNS-серверов и не обращаются к ним перед каждым запросом.
С другой стороны, при использовании двойного стека IP (когда работает и IPv4 и IPv6) может быть вообще не понадобиться прописывать отдельные IPv6 DNS-сервера, так как определение IPv6 адреса может произойти и через IPv4 DNS-сервер. Также в качестве провайдера IPv6 DNS-серверов можно использовать и DHCP-сервер на роутере в локальной сети. Например, на Keenetic сие проделывается через CLI (терминальное подключение) следующими командами:
ipv6 name-server 2606:4700:4700::1111
system configuration save
Первую строчку повторяем по количеству добавляемых DNS-серверов. В случае необходимости удаления добавленного в первой строчке добавляем 'no' и повторяем операцию.
Небольшой штришок по настройке системы для работы со SLAAC. Некоторые авторы добавляют на интерфейс, в моем случае это enp3s0, статический IPV6 адрес из раздаваемого диапазона. Добавить адрес, который будет работать до перезагрузки, можно командой:
ip -6 addr add new_IPv6_address_in_range/64 dev enp3s0
Либо прописать его в конфигурационный файл интерфейсов /etc/network/interfaces:
iface enp3s0 static
address new_IPv6_address_in_range/64
Логика такого действия в том, что при включении RA сам сервер потеряет возможность автоконфигурирования IPv6 адреса от всех RA демонов, включая установленный и на этом же сервере. Однако, как показала практика, сам сервер отлично получает от себя же самого новый IPv6 адрес из раздаваемого диапазона. Причем серверу не нужно даже перезагружаться:
ifconfig
enp3s0: flags=4163 <UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.8.158 netmask 255.255.255.0 broadcast 192.168.8.255
inet6 2a06:XXXX:XXXX:8:7285:c2ff:fe7f:37f5 prefixlen 64 scopeid 0x0 <global>;
inet6 fe80::7285:c2ff:fe7f:37f5 prefixlen 64 scopeid 0x20 <link>;
ether 70:85:c2:7f:37:f5 txqueuelen 1000 (Ethernet)
route48-usp: flags=209 <UP,POINTOPOINT,RUNNING,NOARP> mtu 1420
inet6 2a06:XXXX:XXXX::2 prefixlen 48 scopeid 0x0 <global>
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 1000 (UNSPEC)
В выводе выше видно, что сервер на своем интерфейсе enp3s0 получил IPv6 адрес из раздаваемого диапазона. Причем адрес сформировался с учетом MAC-адреса сетевой карты. Но вернемся к настройкам radvd, я пройдусь по всем настройкам из конфигурационного файла, а полный их перечень можно посмотреть в документации:
AdvSendAdvert on — включение функции анонсирования маршрутизатора и ответы на RS-пакеты. По умолчанию выключено (off).
MaxRtrAdvInterval 300 — максимальное время в секундах в течение которого посылается RA-пакет, без получения RS-пакетов. По умолчанию 600 секунд.
AdvOnLink on — анонсирование возможности маршрутизации пакетов на адреса, выдаваемые по указанному префиксу. Если выключено (off), то адреса из выдаваемого диапазона могут и не быть доступными с этого интерфейса.
AdvAutonomous on — означает необходимость самостоятельной генерации IPv6 адреса из предлагаемого префикса, собственно механизм SLAAC. В противовес необходимо использовать DHCP.
AdvRouterAddr off — если включено, то вместо префикса хостам отправляется адрес интерфейса, что позволяет использовать подключения Mobile IPv6. Mobile IPv6 позволяет мобильным устройствам, смартфонам, ноутбукам или мобильным серверам, если таковые вообще существуют в природе, всегда отвечать по своему «домашнему» IPv6 адресу не взирая к какой IPv6 сети он сейчас подключен. На текущий момент не очень ясно, такая функция вообще у кого-то работает или нет.
AdvValidLifetime 21600 — время в секундах, в течение которого маршрутизация считается действительной. Большинство клиентов принимают минимальное значение за равное 2-м часам.
AdvPreferredLifetime 14400 — время в секундах, в течение которого IPv6 адрес, полученный посредством SLAAC механизма считается приоритетным.
Дополнительный параметр, который имеет смысл рассмотреть AdvDefaultPreference. Этот параметр задает приоритет «этого» IPv6 маршрутизатора над всеми другими, которые могут быть в сети. Значение может быть low, medium или high. Параметр указывается в группе interface. Таким образом клиенты смогут выбирать наиболее предпочтительный маршрутизатор для отправки пакетов во внешний мир в случае, если в сети имеется несколько IPv6 маршрутизаторов. Что и было проверено на сети, где IPv6 уже был от городского провайдера. Провайдерский IPv6 прилетал через RA с medium приоритетом, поэтому после установки AdvDefaultPreference в high туннелированный IPv6 стал основным маршрутом для всех подключенных в сети устройств, которые понимают IPv6.

Ответы RTT при различных видах подключений
Как видно из приведенной картинки IPv4 от провайдера работает медленнее, чем IPv6 от того же провайдера. Туннелированный IPv6 работает медленнее, чем провайдерский, но все равно несколько быстрее, чем IPv4. Замедление скорости на туннелированном IPv6 обуславливается наличием одного, дополнительного узла в моей локальной сети, это Ubuntu-сервер, необходимостью шифрования трафика и последующей его расшифровкой, а так же дополнительным узлом в виде VPS и/или туннельного брокера, через которого идет IPv6 трафик. В данном примере применялся туннельный брокер, расположенный в моем же городе с round trip time до него в 4 мс. Результат очень неплохой.
Для автоматической загрузки radvd необходимо включить сервис:
systemctl enable radvd.service
И его же можно сразу перезапустить (или запустить, если он не был запущен ранее):
systemctl restart radvd.service
Проверить работоспособность radvd можно несколькими способами. Можно воспользоваться утилитой radvdump (устанавливается отдельно), в качестве параметра ей можно передать адрес интерфейса:
radvdump enp3s0
#
# radvd configuration generated by radvdump 2.16
# based on Router Advertisement from fe80::7285:c2ff:fe7f:37f5
# received by interface enp3s0
#
interface enp3s0
{
AdvSendAdvert on;
# Note: {Min,Max}RtrAdvInterval cannot be obtained with radvdump
AdvManagedFlag off;
AdvOtherConfigFlag off;
AdvReachableTime 0;
AdvRetransTimer 0;
AdvCurHopLimit 64;
AdvDefaultLifetime 900;
AdvHomeAgentFlag off;
AdvDefaultPreference medium;
AdvSourceLLAddress on;
prefix 2a06:XXXX:XXXX:8::/64
{
AdvValidLifetime 21600;
AdvPreferredLifetime 14400;
AdvOnLink on;
AdvAutonomous on;
AdvRouterAddr off;
}; # End of prefix definition
RDNSS 2606:4700:4700::1111 2606:4700:4700::1001 2001:4860:4860::8888
{
AdvRDNSSLifetime 300;
}; # End of RDNSS definition
}; # End of interface definition
И после некоторого ожидания на экран будет выдан пакет RA (вот он выше), который ушел в сеть (по таймауту или по запросу какого-либо хоста).
Проверить можно и через отправку ICMP пакетов на «магический» адрес или просто запустив ip -6 n и посмотреть сколько соседей сейчас в сети:
ip -6 n 2a06:XXXX:XXXX:8:80ea:f04:d583:3ff7 dev enp3s0 lladdr b0:c0:90:a2:e4:57 REACHABLE 2a06:XXXX:XXXX:8:5b5:3c1b:a0fb:6824 dev enp3s0 lladdr 80:ee:73:ca:8a:8c STALE 2a06:XXXX:XXXX:8:e618:6bff:fe7a:b261 dev enp3s0 lladdr e4:18:6b:7a:b2:60 STALE 2a06:XXXX:XXXX:8:6231:97ff:fee8:a019 dev enp3s0 lladdr 60:31:97:e8:a0:18 STALE
В выводе я убрал строки относящиеся к Link-local адресам и оставил только полученные через RA-механизм. Здесь указываются IPv6 адреса, в том виде, в котором они были сконфигурированы, интерфейс, на котором присутствуют откликнувшиеся соседи (это интерфейс локальной сети) и MAC-адреса. В конце каждой строки указывается текущий статус устройства (это статус Neighbour Unreachability Detection), он может быть следующим:
Permanent — «сосед» действителен вечно, удалить его можно только руками.
Noarp — «сосед» действителен, но его не проверяли и не будут, он может быть удален из списка по истечению таймаута.
Reachable — «сосед» действителен и он проверен. Статус будет действовать до истечения таймаута действительности.
Stale — «сосед» действителен, по крайней мере был таковым, но на текущий момент его не проверяли.
None — статус «соседа» не определен, его либо только-только добавили в список, либо еще не успели его очистить после удаления.
Incomplete — статус «соседа» еще не был проверен.
Delay — проверка «соседа» задерживается.
Probe — статус «соседа» был проверен.
Failed — проверка «соседа» не удалась.
На практике статусы обычно бывают либо Reachable, либо Stale. У некоторых узлов дополнительно проставляется признак router, что означает, что данный узел является маршрутизатором. В качестве других меток, которые могут быть присвоены узлу могут быть еще proxy, если сервер выступает в качестве proxy для данного узла) и extern_learn в случае, если информация по данному узлу была предоставлена из внешних систем, чтобы это и не значило.
Весь трафик через WireGuard туннель маркируется как некатегоризированный в мониторинге трафика Keenetic
Кстати, работы по внедрению IPv6 проводились за пределами рабочего дня, поэтому в «соседи» попали только «кинетики» да сам сервер.
В результате настройки получаем работающий канал WireGuard для передачи IPv6 трафика и автоматическое конфигурирование адресов IPv6 в локальной сети. В таких условиях применять DHCPv6 вместо SLAAC особого смысла нет. Единственный плюс DHCPv6 то, что он может запоминать назначенные адреса и может работать в сетях меньше, чем /64. Но при этом он требует дополнительной настройки. Именно по этой причине я не буду рассматривать установку и настройку DHCP, тем более что даже при использовании SLAAC (с или без nd_proxy) можно попробовать делить /64 сеть на более мелкие кусочки, ограничивая диапазоны адресов при их конфигурировании со стороны WireGuard.
Работаем с Keenetic
Несмотря на всю мою симпатию к роутерам Keenetic, в данном конкретном сценарии полноценно использовать подобные устройства не выйдет. Причин тут две. Во-первых, до сих пор Keenetic не научились полноценно работать с IPv6 в плане применения WireGuard. Туннель на WireGuard создать можно, но вот нормально завернуть в его трафик IPv6 уже не выйдет. Проблема старая, но разработчики не спешат ее исправлять, так как изменения «под капотом» необходимо проводить серьезные. Как альтернативу можно использовать WireGuard и radvd через менеджер пакетов Entware, который доступен на Keenetic. Но и тут не все так просто. Все, что запускается под Entware работает медленнее, тех модулей, что доступны в основной прошивке для роутера. Во-вторых, сам WireGuard для Entware написан на интерпретируемом языке программирования, что тоже не добавляет ему прыткости. И как следствие обеспечить приемлемую пропускную способность на основе Keenetic не выйдет. И если требуется решить вопрос в рамках одного маршрутизатора, то стоит поискать другое решение, нежели Keenetic.
Пару слов о безопасности
Многих пользователей, да и не пользователей тоже, беспокоит аспект безопасности, который возникает в процессе настройки и эксплуатации сетей. Особо привлекает внимание подключение публичных адресов для всевозможного оборудования. Отчасти эти опасения обоснованы, отчасти нет. Попробуем разобраться, очень поверхностно, так как углубление в тему потребует не одной статьи, со страхами и защитами от злобных хакеров.
Начнем с великих и могучих файерволов. Файервол или брандмауэр — это всего лишь межсетевой экран. Специальный фильтр, который может блокировать или наоборот пропускать пакеты между отдельными сетями. Межсетевой экран может быть «установлен», например, в рамках одной организации, дабы ограничить доступ сотрудников одной подсети, к некоторым ресурсам другой подсети. Но часто межсетевой экран используется для фильтрации трафика на границе глобальной и локальной сетей.
Каков основной аспект межсетевого экрана в плане защиты информационных систем от несанкционированного доступа? Первоначально, компьютеры не были соединены в сети. И никакие экраны не были нужны в принципе. Затем появились компьютерные сети, которые объединили десятки и сотни компьютеров в единые вычислительные организмы. На компьютерах появлялись сервисы, которые становились доступными другим участникам сети. Начали появляться пароли, пользователи и ограничения по правам доступа, чтобы не все могли использовать предоставляемые сервисы по своему желанию и разумению. Все более-менее работало, пока сети не стали большими (тысячи, десятки тысяч, сотни тысяч машин). Вот тогда и появились люди, которым вдруг не понравилось, что их кто-то (владельцы ресурса) ограничивает и не дает пользоваться ресурсами других машин. Разумеется, пошла волна недовольства и наиболее опытные умельцы начали получать несанкционированные доступ к чужим ресурсам и сервисам, так зародились прото-хакеры.
Но как же происходит взлом? Наиболее популярных способ — подбор пароля. Он был популярен еще на заре компьютерных сетей, остается актуальным и сейчас. Компьютеры существенно эволюционировали, а люди остались прежними и ленятся установить сложный пароль, который нельзя подобрать путем перебора. Но, почему если пароль надежный или используются более изощренные средства аутентификации, то все равно обнаруживаются энтузиасты, которые получают доступ туда, куда их не пускают. Как они это делают?
Проблема заключается в самих сервисах и тех языках/платформах, на которых их реализовывали. Человеку свойственно ошибаться, тем более при написании программного обеспечения. А некоторые языки программирования и/или платформы только подталкивают к совершению ошибок. Наиболее популярный способ взлома заключается в переполнении входного буфера сервиса. Сервис ожидает пакет в 1000 байт, а ему послали 15000. 1000 байт уйдет в приемный буфер, а остальное запишется в оперативную память, туда, где хранится выполняемый код. И таким образом компьютер выполнит код хакера, что тому, собственно и нужно. Переполнение буфера далеко не единственный способ, тем более он довольно-таки сложен в исполнении и очень сильно зависит от конкретных версий атакуемого программного обеспечения. Гораздо проще передавать данные сервисам в формате с искажениями. Неверный формат зачастую позволяет прицепить к данным еще и команды на выполнение на стороне сервера сервиса.
Защитит ли тут файервол? Нет, не защитит. Так как если закрыть доступ к сервису для пользователей Интернет, то останутся пользователи в локальной сети. Можно установить файервол и на самом компьютере, закрыв доступ к сервису всем, но тогда ценность такого сервиса будет стремиться к нулю, ведь смысл его существования в том, чтобы им кто-то пользовался. В этом случае сервис вообще не нужен. И что же делать? Рецепт тут прост и сложен одновременно. Необходимо создавать программные продукты в рамках принятых фреймворков, стараться не допускать ошибок в проектировании информационных систем, при их написании. И конечно же тестировать, то, что получилось. Иначе никакой файервол не поможет.
В некоторое заблуждение пользователей вводит встроенный файервол в операционной системе Windows. Он постоянно спрашивает у пользователей, стоит ли давать той или иной программе доступ в сеть. И поэтому создается впечатление, что файерволом должно быть закрыто все. Все порты, все программы на всякий случай, иначе грустный хакер пролезет на компьютер и получит доступ к самому ценному, что на нем хранится. В таком случае нужно понимать, что для того, чтобы хакер хотя бы подключился к нужному ПК, на определенном порту этого ПК должен сидеть какой-то сервис, который будет хотя бы принимать сообщения от кого-то подключившегося. Если такового сервиса нет, то и закрывать порт нет необходимости. Разумеется, если программное обеспечение контролируется, а не устанавливается все подряд из неизвестных источников.
Итак, файервол не защитит от взлома, но поможет обеспечить доступ к определенным ресурсам только для определенных сетевых источников. Ни на что большее, в плане защиты от хакеров файервол не способен. А чем же тогда защищаться? Особенно, если любой компьютер с полученным публичным IPv6 адресом потенциально доступен из любой точки сети, земного шара и МКС. В современных операционных системах с этой целью предпринимается ряд мер. Использование файервола на пользовательском компьютере лишь обеспечивает иллюзию защиты от внешнего подключения. Ведь если на ПК установлено потенциально ненадежное программное обеспечение, которое нужно закрывать при помощи межсетевого экрана, то ничто не помешает этому приложению, если оно действительно деструктивное, передать свои пакеты через другие сетевые средства, доступные в системе. В этом случае действенная защита как раз заключается в не установке такого приложения, а не в блокировании его доступа к сети.
Помимо компьютерной гигиены следует всегда придерживаться использования актуальных версий программного обеспечения. Программисты не всегда едят свой хлеб с икрой просто так, иногда они работают и выпускают исправления, позволяющие закрывать найденные уязвимости в их программных продуктах. В этом ключе обновления программ и операционной системы являются благом и помогают предотвратить более серьезные проблемы с несанкционированным доступ и компрометацию данных. Хотя многие производители, тот же самый Microsoft, зачастую не реагируют на найденные уязвимости до тех пор, пока они не станут критическими (ими активно начинают пользоваться для взлома), либо о них не начнут вещать из каждого утюга и пепельницы.
Что еще? IPv6 адрес уникален в сети. И достаточно зайти на компьютере с IPv6 на веб-сайт и его адрес останется в лог-файлах веб-сервера. Администратор может ознакомиться с адресом и может попытаться подключиться к компьютеру, который заходил к нему на сайт, при помощи этого адреса. Весело. Но не тут-то было. Выше я упоминал, что в операционных системах от Microsoft при помощи SLAAC генерируется IPv6 адрес не привязанный к MAC-адресу сетевого адаптера компьютера. Более того, генерируется два IPv6 адреса. Один — временный, он используется для подключения к внешним системам, именно он останется в лог-файле веб-сервера, второй постоянный и применяется для входящих подключений к этому компьютеру. Делается это по причине физической невозможности перебора всех IPv6 адресов в сети. Их слишком много.
Получается, что наличие публичного IPv6 адреса потенциально ставит под угрозу устаревшие компьютеры с давно не обновляемым программным обеспечением. Потенциально в том плане, что существует незначительно большая вероятность их взлома, нежели без участия IPv6. На регулярно обновляемых ПК, с актуальным программным обеспечением безопасность остается на прежнем уровне, что с IPv6, что без него. Большую опасность несет сам пользователь, особенно малоквалифицированный, но уверенный в своих действиях.
Что до надежности канала WireGuard, то она обеспечивается шифрованием ключами, которые не передаются в открытом виде по сети, за исключением того момента, когда вы их удаленно копируете на сервер или к себе для установки. Но делается это всегда по защищенному каналу. Более того, сам WireGuard периодически изменяет ключи в процессе обмена информацией. Изменение происходит, разумеется, в защищенном туннеле. Поэтому взломать туннель WireGuard без получения доступа к обоим концам туннеля если и можно, то очень не просто и невероятно дорого. А что если туннельный «провайдер» или провайдер VPS будет смотреть трафик? Теоретически это возможно, но на практике лишено какого-либо смысла. Так как практически весь важный трафик идет в зашифрованном виде, например, для просмотра Web-сайтов используется https-протокол, который шифруется посредством сертификатов. Таким образом получается шифрование внутри шифрования. Взломать данную схему опять же очень не просто и куда разумнее осуществлять атаку на самого пользователя, использовать фишинг, подменять DNS и вытворять схожие трюки.
Что на практике (вместо заключения)?
Спустя несколько недель эксплуатации раздачи IPv6 через туннели для нескольких сетей я могу сделать вывод, что схема вполне рабочая. Она рабочая как с получением префикса через туннельного брокера, так и при раздаче адресов с VPS. Причем VPS не обязательно использовать мощный, все VPS начальных уровней на самых недорогих тарифах: 0.5 Гб ОЗУ, 5 ГБ диска, 1 дохленький процессор. При прогонке трафика через VPS с использованием WireGuard нагрузка на сервер минимальная, память не расходуется вообще, процессор загружается в пределах разумного до значений не более 4-8% (при этом простое обращение к страничке этого блога загружает процессор втрое больше). Низкая загрузка обеспечивается работой WireGuard на уровне ядра операционной системы Linux, скромными накладными расходами самого WireGuard. Процессорное время в основном тратится на операции шифрования и дешифрования трафика, прокидывание байтиков между интерфейсами вообще не заметно на загрузке процессора.
В работе с сетью, наличие нормально работающего IPv6 сказалось весьма и весьма положительно. Веб-сайты начали открываться быстрее, пиринговые сервисы получили полноценную возможность работы со входящими подключениями, отклик нагруженных пользовательскими интерфейсами (например, почтовые сервисы) сайтов улучшился. Пришлось даже отказаться от IPv6 канала, который выдал мне один из провайдеров, так как через альтернативное подключение все работает быстрее и стабильнее, нет дикой маршрутизации внутри самого провайдера, обходится нагромождение внутренних прокси и фильтров.
Для получения нормальной, стабильной скорости и быстрого отклика, желательно использовать точки входа WireGuard как можно ближе к собственному местоположению. Например, в моем городе, ping (RTT) до точки обмена составляет 3-4 мс, а если использовать зарубежные площадки, то RTT обычно колеблется от 30 до 80 мс, что тоже вполне приемлемо.
Часть из подключенных локаций использует мобильную сеть для подключения к интернет. Отечественные сотовые операторы не спешат переходить на современные стандарты и видимо смело войдут в 22 век с использованием IPv4. Работа через мобильного оператора имеет свои нюансы в виде периодических отключений, нестабильного и большого RTT. Разумеется, это все сказывается и на туннелированном IPv6, но особо жизнь не портит. Туннель WireGuard восстанавливается быстро, длительных разрывов не наблюдается.
Полезные ссылки
Приведу ссылки на полезные для изучения статьи по теме вопроса, а заодно и на сервисы, которые так или иначе затрагивались при работе над статьей. Часть материалов на русском языке, остальное на английском.
Туннельные брокеры для IPv6
Hurricane Electric
Ipv4market.ru
Route48.org
Деление на сети в IPv6
CIDR и IPv6 наглядно
Калькулятор подсетей IPv6
Подключения WireGuard и IPv6
Bringing the IPv6 Internet to the IPv4-only land of NAT (туннелирование IPv6 на OpenWRT)
Wireguard + OpenWRT + Unbound = дивный новый мир VPN (туннелирование IPv6 с NAT и квитованием пакетов на Windows)
Setup WireGuard with global IPv6 (туннелирование IPv6 через WireGuard с выдачей /128 глобального адреса)
WIREGUARD ALLOWEDIPS CALCULATOR
Прочее
IPv6 – Proxy the neighbors (or come back ARP – we loved you really) работа с proxy_ndp
Пример конфигурации proxy_ndp
Ускорение сети за счет включения BBR
Префиксы в IPv6
IPv6 — это весело. Часть 1. Базовые понятия.
IPv6 — это весело. Часть 2. Маршрутизация. SLAAC и DHCPv6.
Тяжелое расставание с Net-Tools. Разъяснения по поводу использования современных приложений для управления сетью в Linux.
How to: IPv6 Neighbor Discovery
IANA: IPv6 Multicast Address Space Registry
Памятка IPv6 on Windows
Генератор ключей и конфигов online, если лень вводить команды руками.
SLAAC
IPv6 Stateless Address Auto-configuration (SLAAC)
Калькулятор MAC-адреса из IPv6 адреса
How to avoid exposing my MAC address when using IPv6? Каким образом отвязать MAC-адреса от использования их в IPv6 адресах.
Neighbors proxy
IPv6 – Proxy the neighbors (or come back ARP – we loved you really)
IPv6 Neighbour Proxy
Настройка radvd
Параметры конфигурационного файла
Вариант настройки
Еще один вариант настройки со всеми дополнительными компонентами
UPD2023: Route48, к сожалению, все.
Автор фотографии: Д. Княжев


